

Большинство известных ML-алгоритмов относятся к одному из трех основных типов:
- Контролируемое обучение. Обучаемые с учителем алгоритмы строят модель на основе данных, которые уже имеют метки (теги, категории). Эта модель затем используется для прогнозирования меток новых данных. Если метки дискретные (например, «да» или «нет»), то модель будет решать задачу классификации (например, определять, какие сообщения являются спамом). Если же метки непрерывные (числа), то модель будет решать задачу регрессии – к примеру, предсказывать динамику цен на недвижимость.
- Неконтролируемое обучение. Обучаемые без учителя алгоритмы работают с немаркированными данными. Они пытаются найти закономерности или структуры в самих данных без внешней подсказки и решают задачи кластеризации (например, сегментации клиентов), понижения размерности данных, выявления аномалий и скрытых паттернов.
- Обучение с подкреплением. Агент обучается взаимодействовать с окружающей средой для достижения максимального вознаграждения. Модель принимает решения на основе проб и ошибок, получая обратную связь в виде награды или штрафа. Алгоритмы этого типа часто используются в робототехнике и сложных автономных системах, играх (шахматы, Го и т.п.) и управлении (например, трафиком).
Еще есть полуконтролируемое (трансдуктивное), многозадачное и трансферное обучение:
- Полуконтролируемое обучение использует как размеченные, так и неразмеченные данные. Этот подход может значительно повысить точность модели, если размеченных данных мало, как это обычно бывает в медицинской диагностике и компьютерном зрении.
- При многозадачном обучении одна модель обучается на нескольких связанных задачах одновременно. Этот подход может улучшить производительность по каждой задаче за счет использования общих данных и признаков. Применяется в специфических сценариях и областях, где задачи связаны друг с другом, например, в обработке естественного языка и компьютерном зрении.
- При трансферном обучении модель, предварительно обученная на одной задаче, используется для решения другой, связанной задачи. Это особенно полезно, когда данных для обучения новой задаче слишком мало. Пример – остаточные сети ResNet, которые используются для классификации изображений.
Каждый из этих типов имеет свои преимущества, перспективы и область применения. Но по уровню практического использования сейчас лидируют алгоритмы обучения с учителем. Это связано с несколькими факторами:
- Практичность – алгоритмы контролируемого обучения эффективно решают конкретные бизнес-задачи, связанные с классификацией или прогнозированием.
- Интерпретируемость результатов – легче оценить качество модели, когда есть целевая переменная для сравнения.
- Доступность размеченных данных – во многих областях уже существуют большие наборы размеченных данных.
- Зрелость методов – алгоритмы обучения с учителем более развиты и имеют множество эффективных реализаций.
Рассмотрим 6 самых важных алгоритмов контролируемого обучения.
С 28 августа по 4 сентября Proglib Academy приглашает вас на курсы по машинному обучению со скидкой 35%.
- Онлайн-курс по математике для Data Science: Разберитесь в математических концепциях, которые лежат в основе машинного обучения.
- Базовые модели ML и приложения: Узнайте, как применять основные алгоритмы для решения реальных задач.
- Алгоритмы и структуры данных: Освойте навыки, которые позволят вам работать с данными более эффективно.
Линейная регрессия (Linear regression)
Линейная регрессия — самый простой и распространенный ML-алгоритм. Используется для моделирования зависимости между одной или несколькими независимыми переменными (факторами) и зависимой переменной (целевым значением). Работает путем нахождения линейного уравнения, которое лучше всего подходит к данным:
- Простая линейная регрессия предполагает наличие одной независимой переменной и одной зависимой переменной. Например, предсказание стоимости квартиры на основе даты постройки здания.
- Множественная линейная регрессия включает несколько независимых переменных. Например, предсказание цены дома на основе его площади, количества комнат, наличия парковки и расположения.
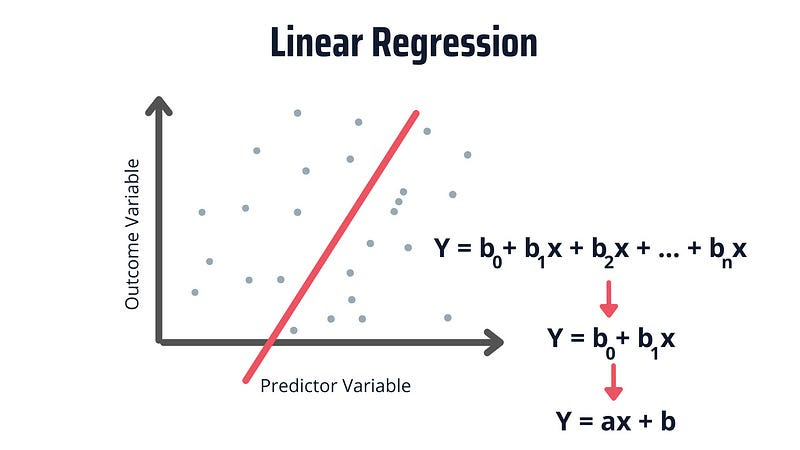
Уравнение множественной линейной регрессии выглядит так:
y = b0 + b1x1 + b2x2 + ... + bnxn
где:
- y — зависимая переменная;
- x1, x2, ..., xn — независимые переменные;
- b0 — свободный член (интерцепт);
- b1, b2, ..., bn — коэффициенты при независимых переменных.
Линейная регрессия часто используется для предсказания численных значений – баллы, зарплаты, цены на жилье. Однако точность предсказаний у этого алгоритма ниже по сравнению с более сложными моделями.
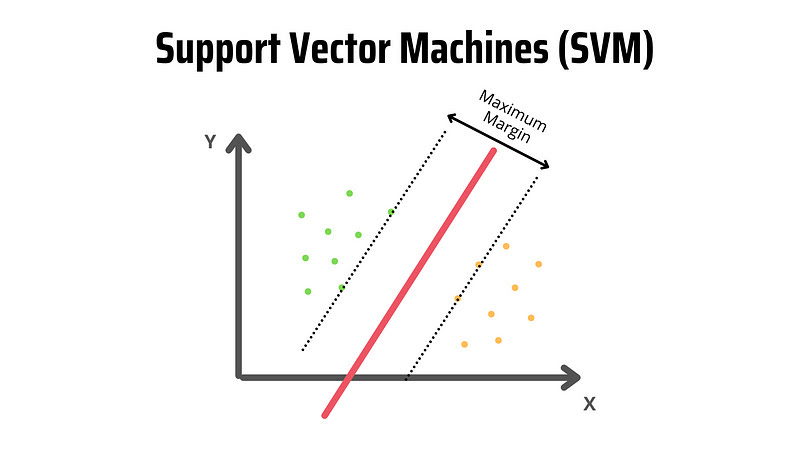
Метод опорных векторов (SVM)
Метод опорных векторов чаще всего используется для задач классификации. Он отлично справляется в ситуациях, когда данных мало, а высокая скорость работы является приоритетом. Основная идея SVM — это создание гиперплоскости, которая лучше всего разделяет классы в многомерном пространстве. Например, если у нас есть два класса данных, каждый из которых представлен в двухмерном пространстве (по осям x и y), SVM будет искать такую линию (в случае двухмерного пространства), которая наилучшим образом разделяет эти два класса. Эта линия называется гиперплоскостью или границей решений.
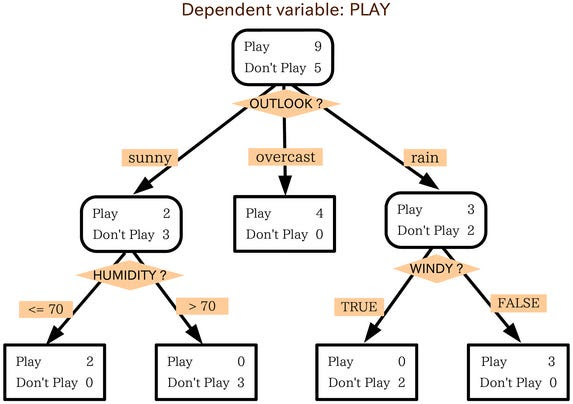
Дерево решений (Decision tree)
Дерево решений используется для принятия решений на основе правил, представленных, как вы уже наверняка догадались, в виде дерева. Каждый узел в дереве представляет собой вопрос или условие, а ветви дерева — возможные ответы или исходы этого вопроса:
- Корень дерева — это начальный узел, с которого начинается процесс принятия решения.
- Внутренние узлы представляют собой условия, которые необходимо проверить.
- Листовые узлы — это конечные узлы, которые представляют собой возможные результаты (предсказания).
Деревья решений используют как для задач классификации, так и для задач регрессии. Они просты для интерпретации, но могут быть подвержены переобучению, особенно если дерево становится слишком глубоким и сложным.
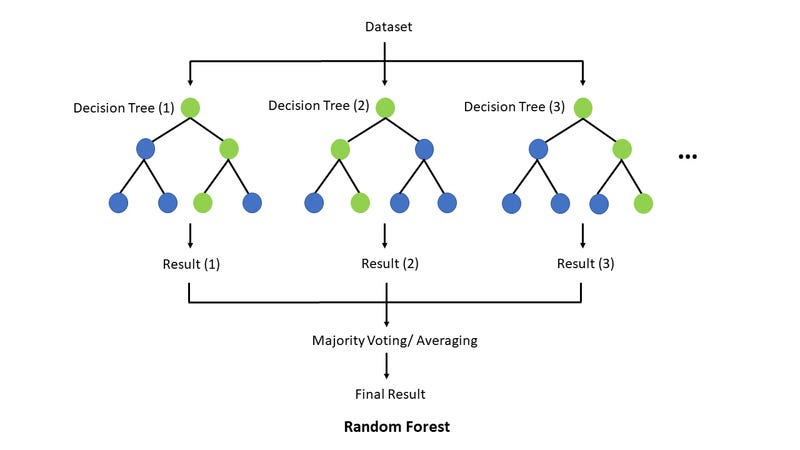
Случайный лес (Random forest)
Случайный лес — ансамблевый метод, который объединяет множество деревьев решений для улучшения точности предсказаний. Идея состоит в том, чтобы создавать несколько деревьев решений на основе разных подвыборок данных (этот процесс называется бутстрэппингом) и затем комбинировать их результаты. Чтобы снизить вероятность переобучения и повысить устойчивость модели, метод случайного леса использует метаалгоритм бэггинга:
- В случае классификации, модель выбирает наиболее часто встречающееся предсказание среди всех деревьев (мода).
- В случае регрессии, модель выбирает среднее значение предсказаний всех деревьев.
Случайный лес показывает более высокую точность, чем одно дерево решений, и хорошо работает с большими наборами данных.
Наивный байесовский классификатор
Наивный Байес предполагает, что все признаки в данных независимы друг от друга, что в реальности не всегда соответствует действительности. Алгоритм основан на теореме Байеса, которая описывает вероятность наступления события A, при условии, что произошло событие B:

Наивный байесовский классификатор часто используется из-за своей простоты и высокой скорости работы, но его точность снижается, если признаки данных оказываются зависимыми друг от друга.
Логистическая регрессия (Logistic Regression)
Логистическая регрессия используется для задач бинарной классификации, где целевая переменная может принимать два значения (например, «да» или «нет», «хот-дог» или «не хот-дог»). Алгоритм основан на логистической функции, также известной как сигмоида, которая преобразует входные данные в вероятность значения между 0 и 1.

Этот алгоритм используется для задач, где важно не только сделать предсказание, но и оценить вероятность того или иного исхода. Например, если вероятность того, что письмо является спамом, равна 0.64, это означает, что вероятность спама составляет 64%. Логистическая регрессия проста для интерпретации и часто используется в различных областях – от спам-фильтров до кредитного скоринга и анализа оттока клиентов.
Есть ли у вас опыт использования этих алгоритмов в реальных задачах? Поделитесь своими впечатлениями в комментариях.
Комментарии