
Распределенные системы обеспечивают масштабируемость и высокую доступность приложений, позволяя обрабатывать запросы пользователей при экстремальном увеличении нагрузки. Однако с ростом сложности таких систем увеличиваются и риски. Как избежать катастрофических отказов, которые могут повредить репутацию компании? Как построить архитектуру, способную выдерживать непредвиденные нагрузки, сбои и атаки? Ответы на эти вопросы лежат в применении стратегий, разработанных специально для обеспечения стабильной работы распределенных систем. Эти стратегии можно разделить на две категории:
- Нисходящие шаблоны – методы, помогающие системе сохранять стабильность при взаимодействии с зависимыми сервисами (например, обработка отказов внешних API или баз данных).
- Восходящие шаблоны – подходы, позволяющие системе эффективно управлять нагрузкой, которую она передает другим сервисам (например, контроль входящего трафика или балансировка нагрузки).
Рассмотрим особенности этих шаблонов подробнее.
Нисходящие шаблоны устойчивости
Нисходящие шаблоны применяются вызывающим сервисом. Они позволяют минимизировать влияние отказов в зависимых сервисах, предотвращая цепную реакцию сбоев в системе. К таким паттернам относятся таймауты, размыкатель цепи и повторные попытки с экспоненциальной задержкой.
Таймауты
Таймаут ограничивает время ожидания ответа от зависимого сервиса. Если сервис не отвечает в течение заданного времени, запрос прерывается, и вызывающий сервис может обработать эту ситуацию (например, вернуть ошибку пользователю или попробовать альтернативный вариант).
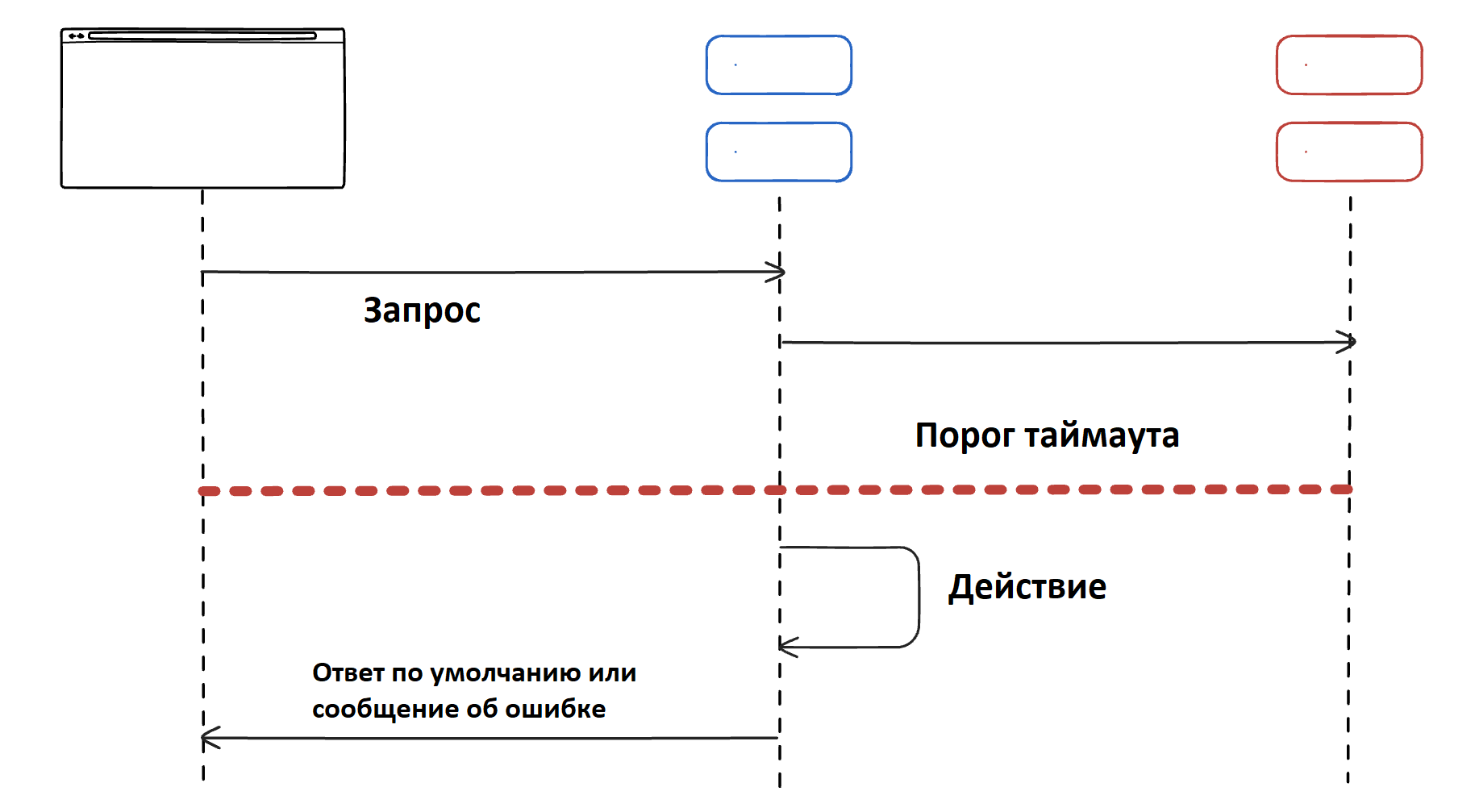
Чем полезна эта стратегия:
- Предотвращает бесконечное ожидание ответа, которое может привести к истощению ресурсов (например, зависшие соединения).
- Повышает отзывчивость системы, так как неудачные запросы быстро завершаются и освобождают ресурсы.
Как реализовать:
- Настраивайте таймауты в зависимости от типа вызова. К примеру, запрос к кэшу может иметь таймаут 50 мс, запрос к базе данных – 500 мс, а для вызова внешнего API можно установить 1000 мс или чуть больше.
- Используйте мониторинг для анализа задержек и корректировки таймаутов.
- Комбинируйте таймауты с другими механизмами устойчивости, например, с повторными попытками и размыкателями цепи.
Предохранитель
Предохранитель отслеживает успешные и неудачные запросы к зависимому сервису. Если количество ошибок превышает заданный порог, вызовы к этому сервису временно блокируются. Это похоже на электрический предохранитель: при перегрузке он «размыкает» цепь микросервисов, чтобы предотвратить дальнейшие сбои.
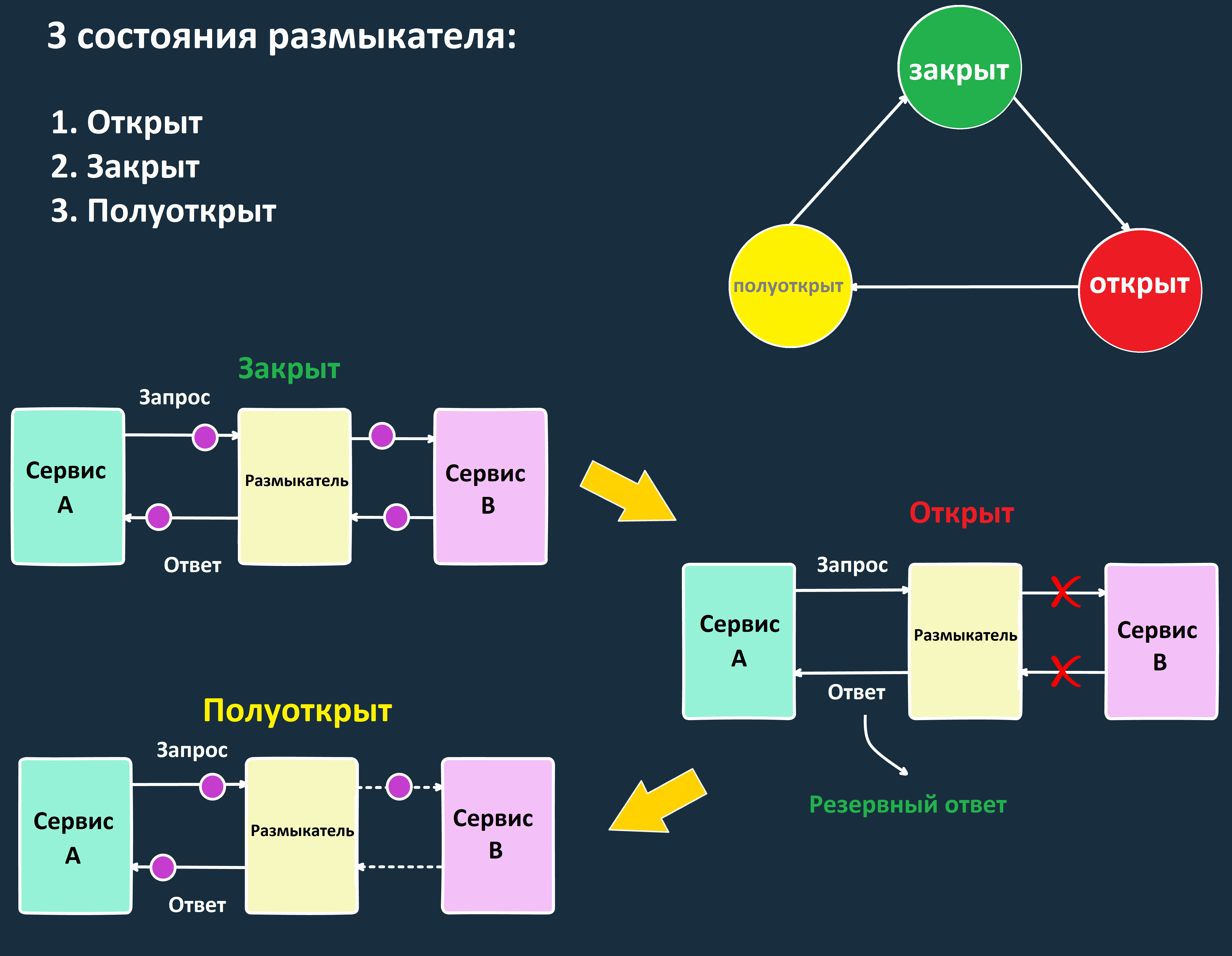
Чем полезна эта стратегия:
- Защищает вашу систему от перегрузки при сбоях в зависимых сервисах.
- Дает зависимому сервису время на восстановление, прежде чем к нему снова начнут поступать запросы.
Как реализовать:
- Используйте готовые библиотеки. Для Java, например, это Resilience4j.
- Определите три состояния размыкателя: «закрыт» – запросы проходят как обычно; «открыт» – запросы блокируются, так как количество ошибок превысило порог; «полуоткрыт» – ограниченное число тестовых запросов отправляется, чтобы проверить, восстановился ли сервис.
- Настраивайте пороги срабатывания – количество ошибок перед срабатыванием размыкателя; временной интервал, в течение которого анализируются ошибки; время ожидания перед попыткой повторного подключения.
Пример: если сервис B перестает отвечать или возвращает ошибки, сервис A перестает отправлять к нему запросы, снижая нагрузку. Через некоторое время предохранитель переключается в состояние «полуоткрыт» и делает несколько пробных запросов. Если они успешны, соединение восстанавливается.
Повторные попытки с экспоненциальной задержкой
Повторные попытки помогают справляться с временными сбоями, если сервис кратковременно недоступен. При использовании экспоненциальной задержки время ожидания перед следующей попыткой увеличивается в два раза после каждого неудачного запроса – это позволяет зависимому сервису восстановиться и снижает нагрузку на него. Метод часто используется при работе с удаленными API, базами данных и очередями сообщений.
Чем полезна эта стратегия:
- Увеличивает вероятность успешного выполнения запроса, если сбой временный.
- Предотвращает перегрузку зависимого сервиса большим количеством повторных запросов.
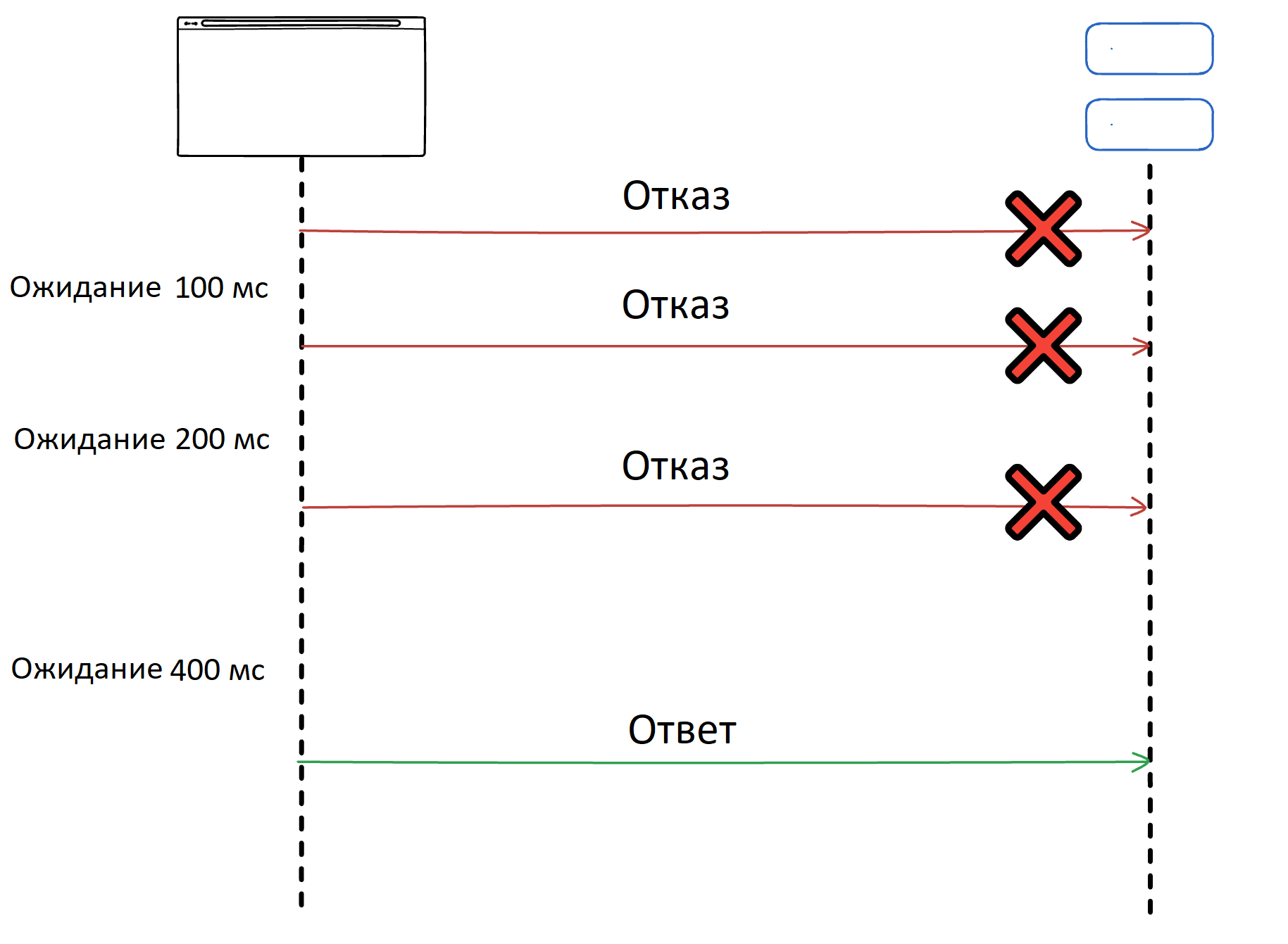
Как реализовать:
- Ограничивайте количество повторов (например, максимум 5 попыток), чтобы избежать бесконечного зацикливания.
- Увеличивайте время задержки случайным образом, чтобы избежать массовых синхронных повторов от разных клиентов (проблема «громового стада»).
Пример: первая попытка – после 100 мс, вторая – спустя 200 мс, третья – через 400 мс, и так далее, пока не будет достигнут лимит.
🚀 Практикум по архитектуре и паттернам через создание игры «Звездные войны»
Интенсив по архитектуре ПО с созданием космического корабля на любом ООП-языке под руководством эксперта-практика.
Ключевые темы интенсива:
- Понимание абстракций и их свойств
- SOLID-принципы с практическими примерами
- Паттерны проектирования на разных языках (C#, Java, Python и др.)
- Модульное тестирование на Mock-объектах
- IoC-контейнеры и управление зависимостями
Восходящие шаблоны устойчивости
Восходящие шаблоны применяются владельцем сервиса, их цель – защитить сервис от перегрузки и обеспечить стабильность при высоком трафике или сбоях. К этим паттернам относятся сбрасывание нагрузки, ограничение количества запросов, переборки и проверка работоспособности с балансировщиком нагрузки.
Сбрасывание нагрузки
Сбрасывание нагрузки – отказ в обработке части входящих запросов, если сервис перегружен. Эта стратегия позволяет системе выдерживать пиковую нагрузку без полного отказа.
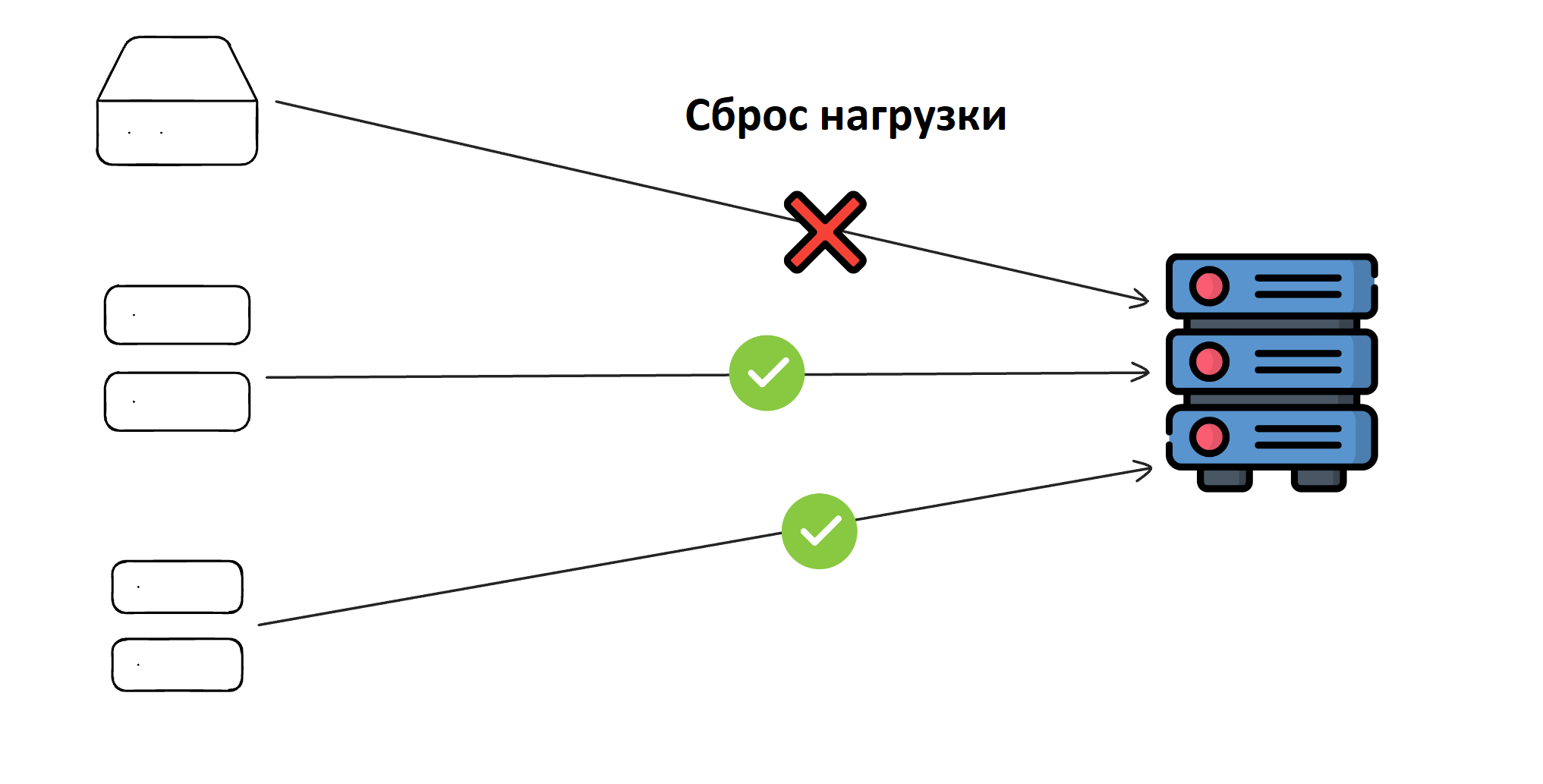
Чем полезна эта стратегия:
- Предотвращает полный отказ системы при пиковых нагрузках.
- Позволяет обрабатывать критически важные запросы в первую очередь (например, платежные транзакции).
Как реализовать:
- Используйте алгоритмы ограничения трафика – ведро с жетонами (регулирует частоту обработки запросов) и текущее ведро (сглаживает пики нагрузки, распределяя запросы равномерно).
- Внедряйте приоритетные очереди, чтобы сначала обрабатывать важные запросы.
- При перегрузке постепенно отключайте менее критичные функции, например, аналитику или фоновые процессы. Можно снизить качество обслуживания (загружать изображения в низком разрешении и т. п.)
Ограничение количества запросов
Этот механизм задает максимальное количество запросов, которое клиент может отправить в определенный промежуток времени.
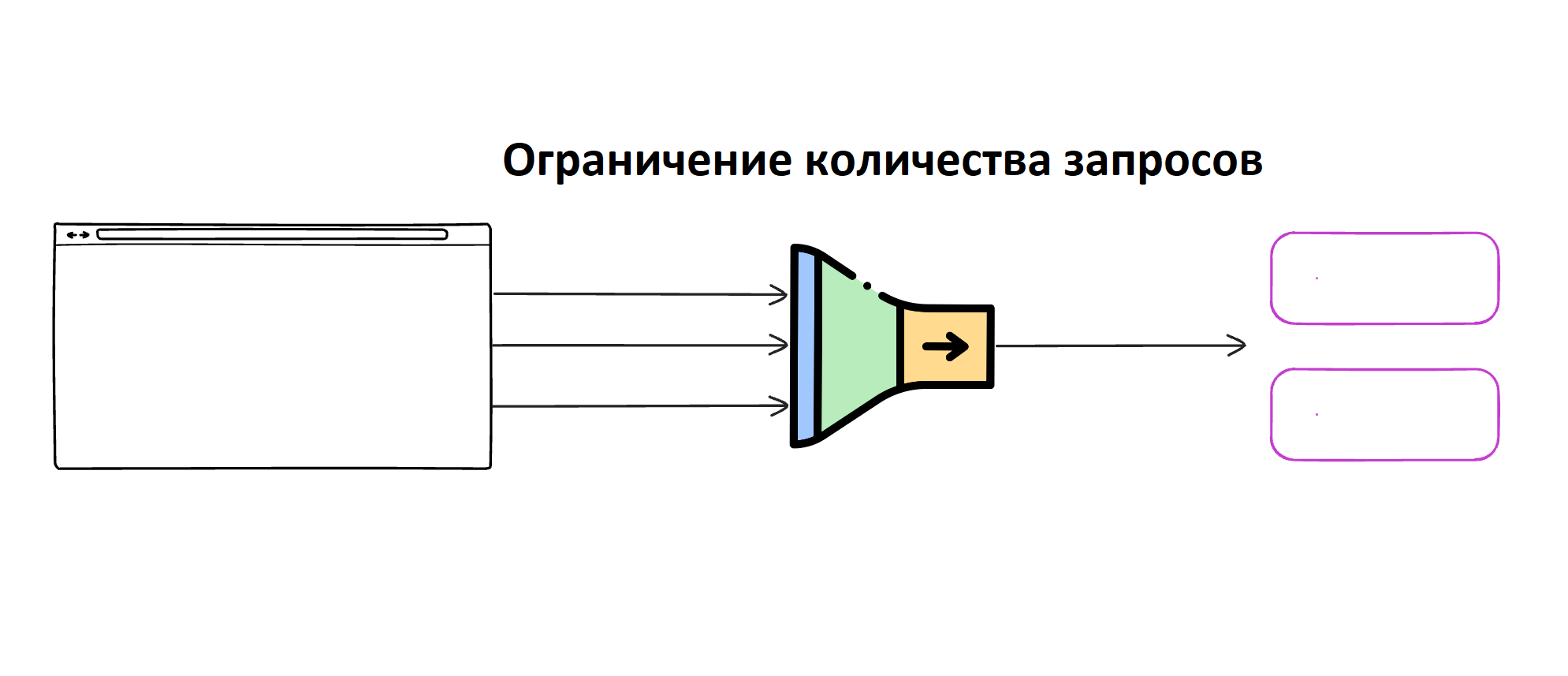
Чем полезна эта стратегия:
- Защищает сервис от злоупотреблений (например, DDoS-атак).
- Обеспечивает справедливое распределение ресурсов между клиентами.
Как реализовать:
- Используйте алгоритмы ограничения трафика – фиксированное окно (ограничение запросов в жестко заданный интервал времени), скользящее окно (более гибкий подход, обновляющий лимиты динамически), ведро с жетонами (позволяет обрабатывать определенное количество запросов за период времени).
- Реализуйте ограничение скорости с помощью API Gateway, NGINX, Kong или других middleware-инструментов.
- Возвращайте клиенту понятные ошибки (например, HTTP 429 Too Many Requests), чтобы он мог адаптировать свою стратегию повторных попыток.
Переборки
Шаблон переборок (отсеков) – это метод изоляции различных частей системы, чтобы сбой в одном компоненте не привел к сбоям в других. Работает так же, как переборки в корабле или подлодке: если одна секция затопляется, остальные остаются неповрежденными и продолжают функционировать.
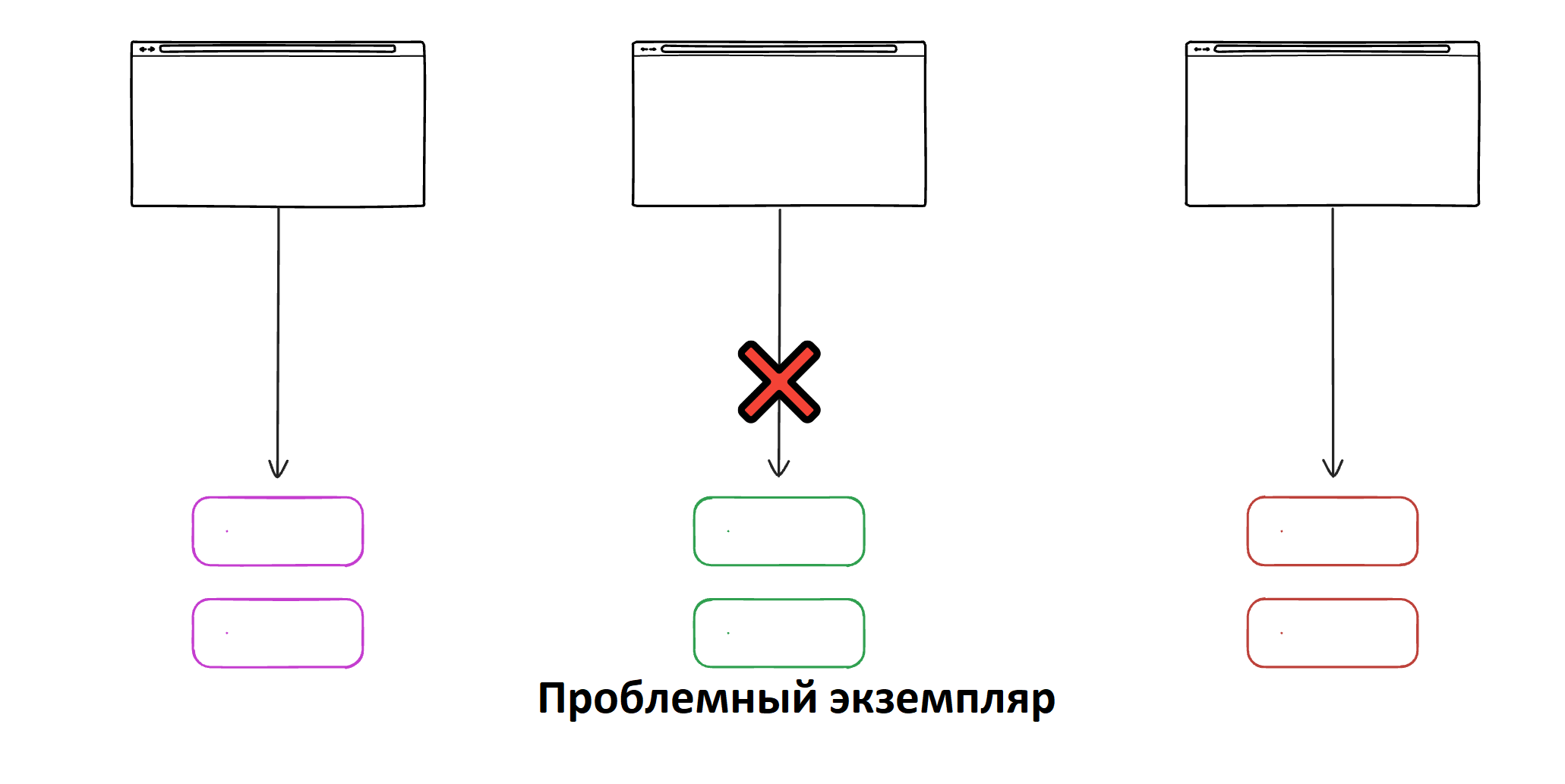
Чем полезна эта стратегия:
- Ограничивает зону поражения при сбоях.
- Повышает устойчивость системы, предотвращая лавинообразное распространение отказов.
- Позволяет системе оставаться работоспособной даже при частичных отказах
Как реализовать:
- Разделяйте пул ресурсов для разных компонентов. Предусмотрите, например, отдельные пулы подключений к базе данных для разных типов запросов (например, критически важные и фоновые).
- Изолируйте критические ресурсы, чтобы низкоприоритетные запросы к некритичным сервисам не могли их исчерпать.
- Используйте оркестрацию контейнеров (например, Kubernetes), чтобы выделять ресурсы (CPU, память) для конкретных сервисов и предотвращать конкуренцию за ресурсы.
Проверка работоспособности с балансировщиком нагрузки
Проверки работоспособности – это механизм мониторинга состояния экземпляров сервиса. Если балансировщик нагрузки обнаруживает, что один из экземпляров вышел из строя, он перенаправляет трафик на другие, исправные экземпляры. Этот подход обеспечивает бесперебойную работу системы и повышает ее надежность.
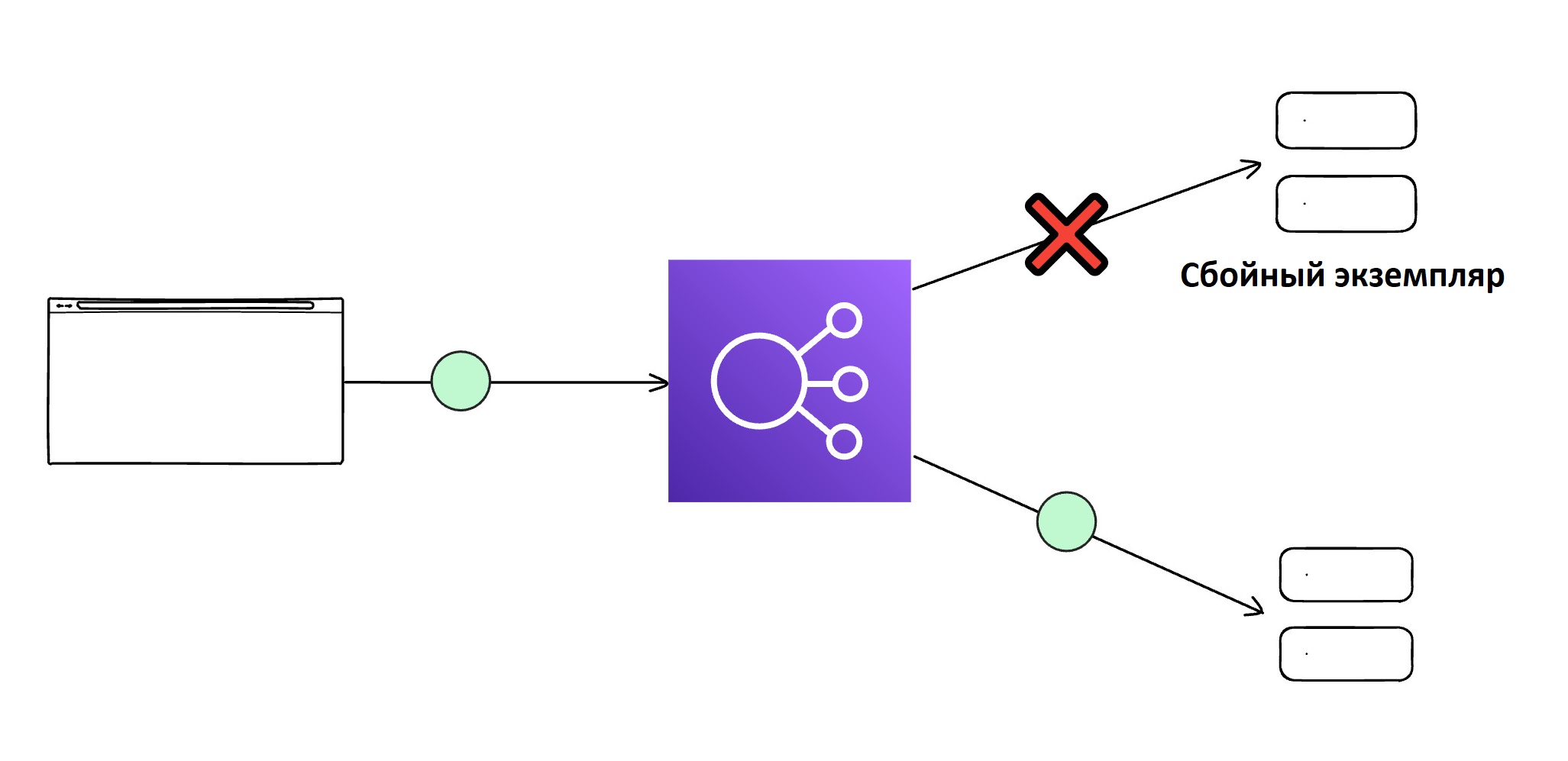
Чем полезна эта стратегия:
- Предотвращает отправку запросов на неработающие или перегруженные экземпляры.
- Минимизирует время простоя и улучшает пользовательский опыт.
Как реализовать:
- Используйте активные и пассивные проверки. Для активной проверки балансировщик периодически отправляет запросы (ping, HTTP-запросы, проверки базы данных). В ходе пассивной проверки балансировщик анализирует ошибки и задержки в реальных запросах.
- Настраивайте пороги проверки, например, число неудачных попыток перед тем, как экземпляр будет считаться «неисправным». Проверяйте время отклика – если оно превышает допустимый предел, экземпляр считается перегруженным.
- Используйте постепенные обновления с проверками работоспособности, чтобы апдейты сервисов происходили без простоев.
В заключение
Построение
устойчивых распределенных систем – это комплексная задача, требующая
тщательного планирования и применения проверенных практик. Рассмотренные нами
семь стратегий – от таймаутов до балансировки нагрузки – формируют надежный
фундамент для создания отказоустойчивых систем. Важно помнить, что эти
стратегии не являются взаимоисключающими – наибольшую эффективность они
демонстрируют при совместном использовании, создавая многоуровневую защиту от
различных типов сбоев. Правильная реализация описанных паттернов позволит системе выдерживать пиковые нагрузки и обрабатывать критически важные задачи, обеспечивая непрерывность
бизнес-процессов и высокое качество обслуживания пользователей.
Комментарии