

Pod
В чем же различие между подом и контейнером? Под может включать в себя несколько контейнеров. Такая конфигурация позволяет реализовать паттерн Side Car, чтобы добавить к поду, например, особый сетевой proxy, сетевую телеметрию и т.д. Под – это своего рода среда выполнения одного или нескольких контейнеров. Использование Side Car диктует паттерны проектирования микросервисов, которые в одной ситуации могут эффективно решать задачи, а в другой станут избыточными.
Изучим жизненный цикл пода в кластере k8s. Процесс появления нового пода показан на схеме.
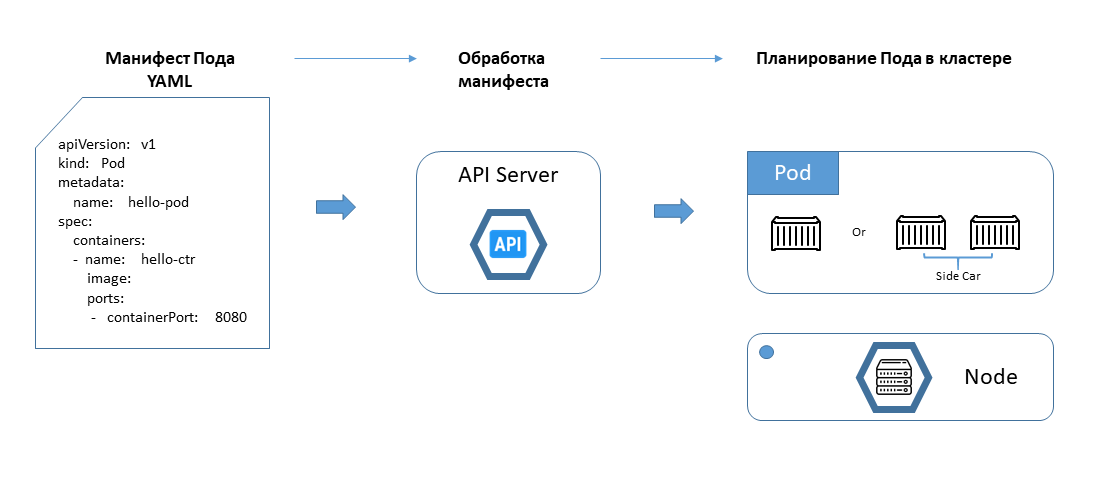
На первом этапе мы описываем под в манифесте на языке YAML. Туда включаются такие параметры как версия API, имя пода, необходимые ресурсы (CPU, RAM, HDD), исполняемый контейнер (image) и многое другое. Подробнее с манифестами мы познакомимся в следующих статьях. В итоге должен получится файл YAML, где декларативно описано будущее приложение или сервис.
Следующий этап – это обработка манифеста сервером API. Если валидация проходит успешно, сервер передает инструкций в Sheduller. В зависимости от запрошенных в поде ресурсов тот подбирает подходящую ноду (узел кластера) для размещения. Можно провести аналогию с заселением в отель и распределением на ресепшене – в какой именно номер вас распределят.
Deployment
Пока мы не видим особо разницы между Docker compose и k8s. Есть контейнеры в Docker, есть поды в k8s – просто одни и те же объекты называются по-разному. Чем же крут k8s? В нем есть Deployment, что дает нам следующие преимущества:
- надежность за счет автоматического процесса поддержки заданного количества подов для приложения;
- масштабируемость;
- нулевой простой приложения при обновлениях.
С надежностью и масштабируемостью разобрались. Как мы получаем нулевой простой приложения при обновлениях?
Функциональность объекта Deployment позволяет выстроить процесс контролируемого изменения и свести к минимуму нужное для него время. Как и любой объект кластера K8s, Deployment описывается декларативно в файле YAML (примеры разберем в следующих статьях).
Service
Работает это через т.н. Labels. У каждого пода или группы подов есть своя уникальная метка, и создавая объект Service, мы указываем, какую метку он обслуживает. Тем самым за сервисом мы закрепляем определенных подов.
Service бывают:
- ClusterIP – стандартный тип, который назначается по умолчанию. Необходим для взаимодействия по сети внутри кластера.
- NodePort необходим для внешнего взаимодействия.
- LoadBalanser необходим для интеграции с облачными балансировщиками нагрузки.
Допустим у вас есть текущая (v0.1) версия приложения (2 пода, разбросанных по разным нодам). Мы развернули и протестировали следующую версию (v0.2). Стоит задача переключить нее входящий трафик.
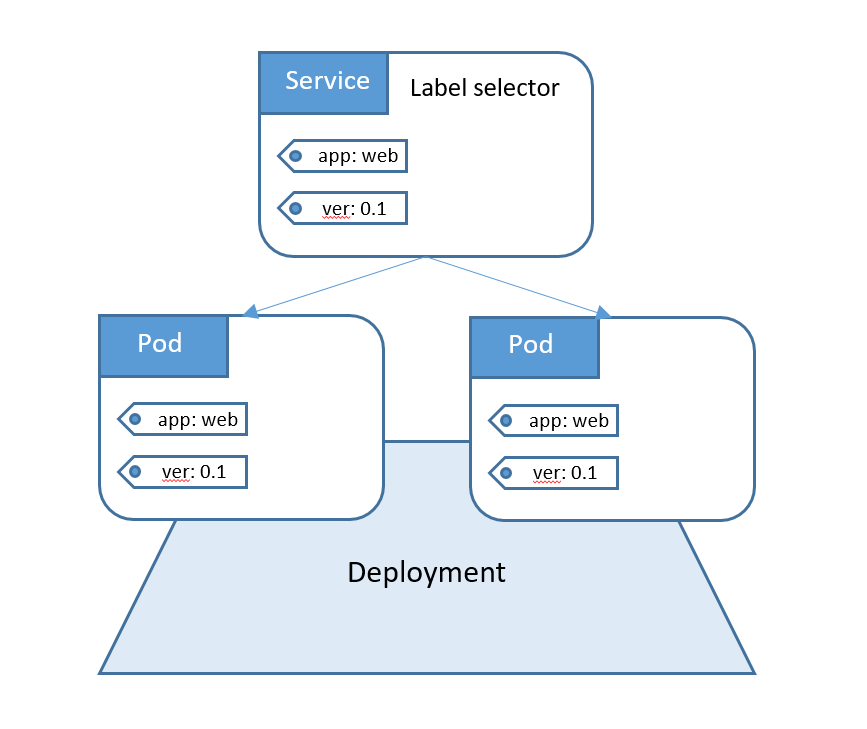
Теперь переключаем входящий трафик на новую версию приложения, изменив Label Selector в Service. В результате трафик будут обрабатывать поды новой версии приложения.
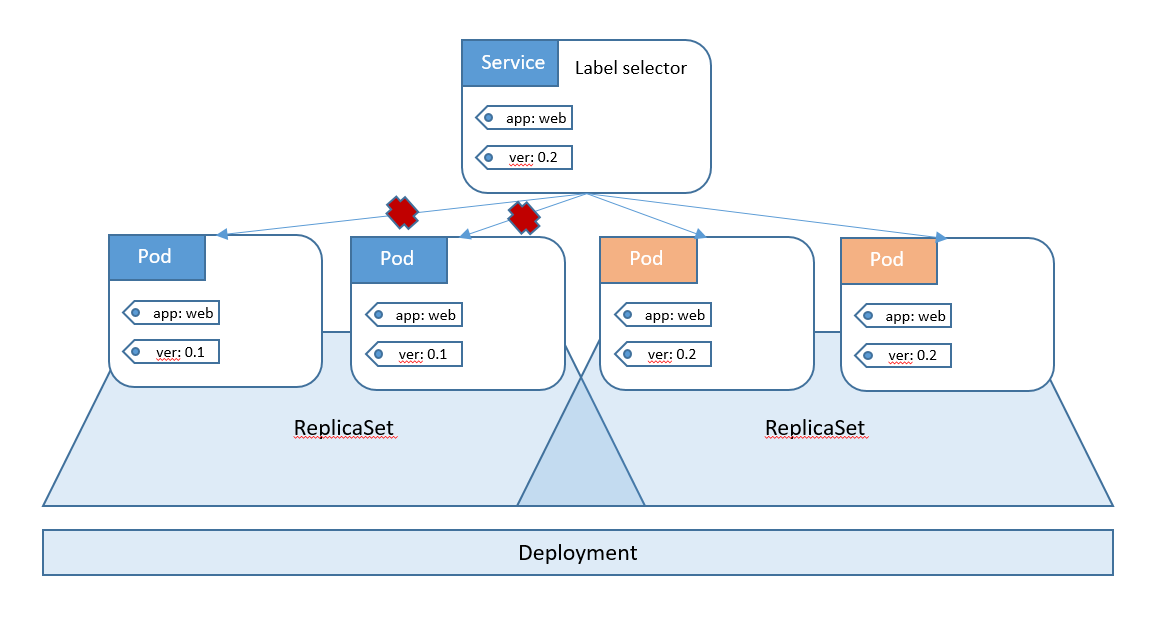
Мы познакомились с основными объектами кластера Kubernetes – это Pod, Deployment и Service. На самом деле объектов гораздо больше, но для развертывания первого приложения в кластере этих будет достаточно. В следующей статье мы напишем Deployment и Service для первого приложения и развернем его в кластере.
Комментарии