
🔍 🎥 Распознавание объектов с помощью YOLO v3 на Tensorflow 2.0
Статья описывает распознавание объектов в изображениях с помощью популярной модели YOLO. Приводится подробное описание архитектуры модели и код, реализующий YOLO v3 на Tensorflow 2.0

Распознавание объектов с помощью YOLO v3 на Tensorflow 2.0
До Yolo большинство подходов к распознаванию объектов заключалось в попытках адаптировать классификаторы к распознаванию. В YOLO, распознавание объектов было реализовано как задача регрессии к раздельным ограничивающим рамкам, с которыми связаны вероятности принадлежности к разным классам. Ниже мы познакомимся с моделью распознавания объектов YOLO и методом ее реализации в Tensorflow 2.0.
О YOLO: Наша обобщенная архитектура чрезвычайно быстра. Базовая модель YOLO обрабатывает изображения в реальном времени со скоростью 45 фреймов в секунду. Меньшая версия модели, Fast YOLO, обрабатывает целых 155 фреймов в секунду…
Что такое YOLO?
YOLO – это передовая сеть для распознавания объектов (object detection), разработанная Джозефом Редмоном (Joseph Redmon). Главное, что отличает ее от других популярных архитектур – это скорость. Модели семейства YOLO действительно быстрые, намного быстрее R-CNN и других. Это значит, что мы можем распознавать объекты в реальном времени.
Во время первой публикации (в 2016 году) YOLO имела передовую mAP (mean Average Precision), по сравнению с такими системами, как R-CNN и DPM. С другой стороны, YOLO с трудом локализует объекты точно. Тем не менее, она обучается общему представлению объектов. В новой версии как скорость, так и точность системы были улучшены.
YOLO преобразовала задачу распознавания объектов к единой задаче регрессии. Она проходит прямо от пикселей изображения до координат содержащих рамок и вероятностей классов. Таким образом, единая CNN предсказывает множество содержащих рамок и вероятности классов для этих рамок.
Теория
Поскольку YOLO смотрит на изображение только один раз, плавающее окно – это неправильный подход. Вместо этого, все изображение разбивается с помощью сетки на ячейки размером 𝑆∗𝑆. После этого каждая ячейка отвечает за предсказание нескольких вещей
Во-первых, каждая ячейка отвечает за предсказание нескольких содержащих рамок и показателя уверенности (confidence) для каждой из них – другими словами, это вероятность того, что данная рамка содержит объект. Если в какой-то ячейке сетки объектов нет, то очень важно, чтобы confidence для этой ячейки был очень малым.
Когда мы визуализируем все эти предсказания, мы получаем карту всех объектов и набор содержащих рамок, ранжированных по их confidence.
Во-вторых, каждая ячейка отвечает за предсказание вероятностей классов. Это не значит, что какая-то ячейка содержит какой-то объект, это всего лишь вероятность. Таким образом, если ячейка сети предсказывает автомобиль, это не значит, что он там есть, но это значит, что если там есть какой-то объект, то это автомобиль.
Давайте опишем детально, как может выглядеть выдаваемый моделью результат.
В YOLO для предсказания содержащих рамок используются якорные рамки (anchor boxes). Их основная идея заключается в предопределении двух разных рамок, называемых якорными рамками или формой якорных рамок. Это позволяет нам ассоциировать два предсказания с этими якорными рамками. В общем, мы можем использовать и большее количество якорных рамок (пять или даже больше). Якоря были рассчитаны на датасете COCO с помощью k-means кластеризации.
У нас есть сетка, каждая ячейка которой должна предсказать:
- для каждой содержащей рамки: 4 координаты (𝑡𝑥,𝑡𝑦,𝑡𝑤,𝑡ℎ) и одну "ошибку объектности" – то есть, метрику confidence, определяющую, есть объект или нет.
- некоторое количество вероятностей классов.
Если есть некоторое смещение относительно верхнего левого угла 𝑐𝑥,𝑐𝑦, то эти предсказания соответствуют следующим формулам:
где 𝑝𝑤 и 𝑝ℎ соответствуют ширине и высоте содержащей рамки. Вместо предсказания смещений, как было во второй версии YOLO, авторы предсказывают координаты локации относительно расположения ячейки сети.
Этот вывод – это вывод нашей нейронной сети. Всего там 𝑆∗𝑆∗[𝐵∗(4+1+𝐶)] выводов, где 𝐵 – количество содержащих рамок, предсказываемых каждой ячейкой (зависит от того, в скольких масштабах мы хотим делать наши предсказания), 𝐶 – количество классов, 4 – количество содержащих рамок, а 1 – предсказание объектности. За один проход мы можем пройти от исходного изображения до выходного тензора, соответствующего распознанным объектам изображения. Стоит также упомянуть, что YOLO v3 предсказывает рамки в трех разных масштабах.
Теперь, если мы возьмем вероятности и умножим их на значения confidence, мы получим все содержащие рамки, взвешенные по их вероятности содержания этого объекта.
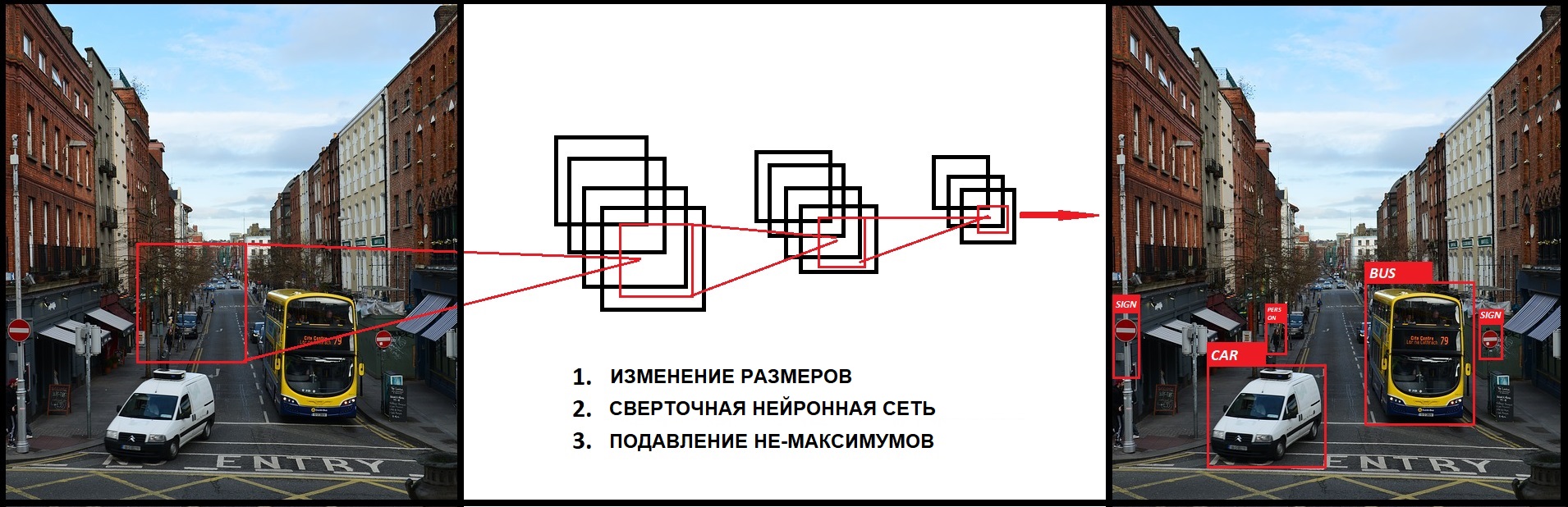
Простое сравнение с порогом позволит нам избавиться от предсказаний с низкой confidence. Для следующего шага важно определить, что такое пересечение относительно объединения (intersection over union). Это отношение площади пересечения прямоугольников к площади их объединения:
После этого у нас еще могут быть дубликаты, и чтобы от них избавиться, мы применяем подавление не-максимумов. Подавление не-максимумов берет содержащую рамку с максимальной вероятностью и смотрит на другие содержащие рамки, расположенные близко к первой. Ближайшие рамки с максимальным пересечением относительно объединения с первой рамкой будут подавлены.
Поскольку все делается за один проход, модель работает почти с такой же скоростью, как классификация. Кроме того, все предсказания производятся одновременно, а это значит, что модель неявно встраивает в себя глобальный контекст. Проще говоря, модель может усвоить, какие объекты обычно встречаются вместе, относительные размеры и расположение объектов и так далее.
Мы настоятельно рекомендуем изучить все три документа YOLO:
- You Only Look Once: унифицированное распознавание объектов в реальном времени
- YOLO 9000: быстрее, лучше, сильнее
- YOLOv3: постепенное улучшение
Реализация YOLO в Tensorflow
Мы создадим полную сверточную нейронную сеть (Fully Convolutional Network, FCN) без тренировки. Чтобы что-то предсказать с помощью этой сети, нужно загрузить веса от заранее тренированной модели. Эти веса получены после тренировки YOLOv3 на датасете COCO (Common Objects in Context), и их можно загрузить с официального сайта.
!wget https://pjreddie.com/media/files/yolov3.weights
Создаем папку для хранения весов
#!rm -rf checkpoints !mkdir checkpoints
Импортируем все необходимые библиотеки
import cv2 import numpy as np import tensorflow as tf from absl import logging from itertools import repeat from tensorflow.keras import Model from tensorflow.keras.layers import Add, Concatenate, Lambda from tensorflow.keras.layers import Conv2D, Input, LeakyReLU from tensorflow.keras.layers import MaxPool2D, UpSampling2D, ZeroPadding2D from tensorflow.keras.regularizers import l2 from tensorflow.keras.losses import binary_crossentropy from tensorflow.keras.losses import sparse_categorical_crossentropy
Проверяем версию Tensorflow. Она должна быть не ниже 2.0:
print(tf.__version__) # 2.1.0
Определим несколько важных переменных, которые будем использовать ниже.
yolo_iou_threshold = 0.6 # порог пересечения относительно объединения (iou) yolo_score_threshold = 0.6 weightsyolov3 = 'yolov3.weights' # путь к файлу весов weights= 'checkpoints/yolov3.tf' # путь к файлу checkpoint'ов size= 416 # приводим изображения к этому размеру checkpoints = 'checkpoints/yolov3.tf' num_classes = 80 # количество классов в модели
Список слоев в YOLOv3 FCN — Fully Convolutional Network
YOLO_V3_LAYERS = [ 'yolo_darknet', 'yolo_conv_0', 'yolo_output_0', 'yolo_conv_1', 'yolo_output_1', 'yolo_conv_2', 'yolo_output_2', ]
Очень трудно загрузить веса с помощью чисто функционального API, поскольку порядок слоев в Darknet и tf.keras различаются. Здесь лучшее решение – создание подмоделей в keras. Для сохранения подмоделей рекомендуется использовать Checkpoint'ы Tensorflow, поскольку они официально поддерживаются Tensorflow.
Вот функция для загрузки весов из оригинальной тренированной модели YOLO в Darknet:
def load_darknet_weights(model, weights_file):
wf = open(weights_file, 'rb')
major, minor, revision, seen, _ = np.fromfile(wf, dtype=np.int32, count=5)
layers = YOLO_V3_LAYERS
for layer_name in layers:
sub_model = model.get_layer(layer_name)
for i, layer in enumerate(sub_model.layers):
if not layer.name.startswith('conv2d'):
continue
batch_norm = None
if i + 1 < len(sub_model.layers) and \
sub_model.layers[i + 1].name.startswith('batch_norm'):
batch_norm = sub_model.layers[i + 1]
logging.info("{}/{} {}".format(
sub_model.name, layer.name, 'bn' if batch_norm else 'bias'))
filters = layer.filters
size = layer.kernel_size[0]
in_dim = layer.input_shape[-1]
if batch_norm is None:
conv_bias = np.fromfile(wf, dtype=np.float32, count=filters)
else:
bn_weights = np.fromfile(
wf, dtype=np.float32, count=4 * filters)
bn_weights = bn_weights.reshape((4, filters))[[1, 0, 2, 3]]
conv_shape = (filters, in_dim, size, size)
conv_weights = np.fromfile(
wf, dtype=np.float32, count=np.product(conv_shape))
conv_weights = conv_weights.reshape(
conv_shape).transpose([2, 3, 1, 0])
if batch_norm is None:
layer.set_weights([conv_weights, conv_bias])
else:
layer.set_weights([conv_weights])
batch_norm.set_weights(bn_weights)
assert len(wf.read()) == 0, 'не удалось прочитать все данные'
wf.close()
Функция для расчета пересечения относительно объединения
def interval_overlap(interval_1, interval_2):
x1, x2 = interval_1
x3, x4 = interval_2
if x3 < x1:
return 0 if x4 < x1 else (min(x2,x4) - x1)
else:
return 0 if x2 < x3 else (min(x2,x4) - x3)
def intersectionOverUnion(box1, box2):
intersect_w = interval_overlap([box1.xmin, box1.xmax], [box2.xmin, box2.xmax])
intersect_h = interval_overlap([box1.ymin, box1.ymax], [box2.ymin, box2.ymax])
intersect_area = intersect_w * intersect_h
w1, h1 = box1.xmax-box1.xmin, box1.ymax-box1.ymin
w2, h2 = box2.xmax-box2.xmin, box2.ymax-box2.ymin
union_area = w1*h1 + w2*h2 - intersect_area
return float(intersect_area) / union_area
Функция для отрисовки содержащей рамки, имени класса и вероятности:
def draw_outputs(img, outputs, class_names):
boxes, score, classes, nums = outputs
boxes, score, classes, nums = boxes[0], score[0], classes[0], nums[0]
wh = np.flip(img.shape[0:2])
for i in range(nums):
x1y1 = tuple((np.array(boxes[i][0:2]) * wh).astype(np.int32))
x2y2 = tuple((np.array(boxes[i][2:4]) * wh).astype(np.int32))
img = cv2.rectangle(img, x1y1, x2y2, (255, 0, 0), 2)
img = cv2.putText(img, '{} {:.4f}'.format(
class_names[int(classes[i])], score[i]),
x1y1, cv2.FONT_HERSHEY_COMPLEX_SMALL, 1, (0, 0, 255), 2)
return img
Мы используем пакетную нормализацию (batch normalization), чтобы нормализовать результаты для ускорения тренировки. К сожалению, tf.keras.layers.BatchNormalization работает не очень хорошо для transfer learning, поэтому здесь предлагается другое решение этой проблемы.
class BatchNormalization(tf.keras.layers.BatchNormalization):
def call(self, x, training=False):
if training is None: training = tf.constant(False)
training = tf.logical_and(training, self.trainable)
return super().call(x, training)
Для каждого масштаба мы определяем три якорные рамки для каждой ячейки. В этом примере маска такова:
- 0,1,2 – мы будем использовать три первые якорные рамки
- 3,4,5 – мы используем четвертую, пятую и шестую рамки
- 6,7,8 – мы используем седьмую, восьмую и девятую рамки
Реализация YOLO v3
Пришло время реализовать сеть YOLOv3. Вот как выглядит ее структура:
Здесь основная идея – использовать только сверточные слои. Их там 53, так что проще всего создать функцию, в которую мы будем передавать важные параметры, изменяющиеся от слоя к слою.
Остаточные блоки (Residual blocks) на диаграмме архитектуры YOLOv3 используются для обучения признакам. Остаточный блок состоит из нескольких сверточных слоев и обходных путей:
Мы строим нашу модель с помощью Функционального API, простого в использовании. С ним мы можем легко задавать ветви в нашей архитектуре (блок ResNet) и легко использовать одни и те же слои несколько раз внутри архитектуры.
def DarknetConv(x, filters, size, strides=1, batch_norm=True):
if strides == 1:
padding = 'same'
else:
x = ZeroPadding2D(((1, 0), (1, 0)))(x) # top left half-padding
padding = 'valid'
x = Conv2D(filters=filters, kernel_size=size,
strides=strides, padding=padding,
use_bias=not batch_norm, kernel_regularizer=l2(0.0005))(x)
if batch_norm:
x = BatchNormalization()(x)
x = LeakyReLU(alpha=0.1)(x)
return x
def DarknetResidual(x, filters):
previous = x
x = DarknetConv(x, filters // 2, 1)
x = DarknetConv(x, filters, 3)
x = Add()([previous , x])
return x
def DarknetBlock(x, filters, blocks):
x = DarknetConv(x, filters, 3, strides=2)
for _ in repeat(None, blocks):
x = DarknetResidual(x, filters)
return x
def Darknet(name=None):
x = inputs = Input([None, None, 3])
x = DarknetConv(x, 32, 3)
x = DarknetBlock(x, 64, 1)
x = DarknetBlock(x, 128, 2)
x = x_36 = DarknetBlock(x, 256, 8)
x = x_61 = DarknetBlock(x, 512, 8)
x = DarknetBlock(x, 1024, 4)
return tf.keras.Model(inputs, (x_36, x_61, x), name=name)
def YoloConv(filters, name=None):
def yolo_conv(x_in):
if isinstance(x_in, tuple):
inputs = Input(x_in[0].shape[1:]), Input(x_in[1].shape[1:])
x, x_skip = inputs
x = DarknetConv(x, filters, 1)
x = UpSampling2D(2)(x)
x = Concatenate()([x, x_skip])
else:
x = inputs = Input(x_in.shape[1:])
x = DarknetConv(x, filters, 1)
x = DarknetConv(x, filters * 2, 3)
x = DarknetConv(x, filters, 1)
x = DarknetConv(x, filters * 2, 3)
x = DarknetConv(x, filters, 1)
return Model(inputs, x, name=name)(x_in)
return yolo_conv
def YoloOutput(filters, anchors, classes, name=None):
def yolo_output(x_in):
x = inputs = Input(x_in.shape[1:])
x = DarknetConv(x, filters * 2, 3)
x = DarknetConv(x, anchors * (classes + 5), 1, batch_norm=False)
x = Lambda(lambda x: tf.reshape(x, (-1, tf.shape(x)[1], tf.shape(x)[2],
anchors, classes + 5)))(x)
return tf.keras.Model(inputs, x, name=name)(x_in)
return yolo_output
def yolo_boxes(pred, anchors, classes):
grid_size = tf.shape(pred)[1]
box_xy, box_wh, score, class_probs = tf.split(pred, (2, 2, 1, classes), axis=-1)
box_xy = tf.sigmoid(box_xy)
score = tf.sigmoid(score)
class_probs = tf.sigmoid(class_probs)
pred_box = tf.concat((box_xy, box_wh), axis=-1)
grid = tf.meshgrid(tf.range(grid_size), tf.range(grid_size))
grid = tf.expand_dims(tf.stack(grid, axis=-1), axis=2)
box_xy = (box_xy + tf.cast(grid, tf.float32)) / tf.cast(grid_size, tf.float32)
box_wh = tf.exp(box_wh) * anchors
box_x1y1 = box_xy - box_wh / 2
box_x2y2 = box_xy + box_wh / 2
bbox = tf.concat([box_x1y1, box_x2y2], axis=-1)
return bbox, score, class_probs, pred_box
Подавление не-максимумов
def nonMaximumSuppression(outputs, anchors, masks, classes):
boxes, conf, out_type = [], [], []
for output in outputs:
boxes.append(tf.reshape(output[0], (tf.shape(output[0])[0], -1, tf.shape(output[0])[-1])))
conf.append(tf.reshape(output[1], (tf.shape(output[1])[0], -1, tf.shape(output[1])[-1])))
out_type.append(tf.reshape(output[2], (tf.shape(output[2])[0], -1, tf.shape(output[2])[-1])))
bbox = tf.concat(boxes, axis=1)
confidence = tf.concat(conf, axis=1)
class_probs = tf.concat(out_type, axis=1)
scores = confidence * class_probs
boxes, scores, classes, valid_detections = tf.image.combined_non_max_suppression(
boxes=tf.reshape(bbox, (tf.shape(bbox)[0], -1, 1, 4)),
scores=tf.reshape(
scores, (tf.shape(scores)[0], -1, tf.shape(scores)[-1])),
max_output_size_per_class=100,
max_total_size=100,
iou_threshold=yolo_iou_threshold,
score_threshold=yolo_score_threshold
)
return boxes, scores, classes, valid_detections
Основная функция, создающая всю модель:
def YoloV3(size=None, channels=3, anchors=yolo_anchors,
masks=yolo_anchor_masks, classes=80, training=False):
x = inputs = Input([size, size, channels])
x_36, x_61, x = Darknet(name='yolo_darknet')(x)
x = YoloConv(512, name='yolo_conv_0')(x)
output_0 = YoloOutput(512, len(masks[0]), classes, name='yolo_output_0')(x)
x = YoloConv(256, name='yolo_conv_1')((x, x_61))
output_1 = YoloOutput(256, len(masks[1]), classes, name='yolo_output_1')(x)
x = YoloConv(128, name='yolo_conv_2')((x, x_36))
output_2 = YoloOutput(128, len(masks[2]), classes, name='yolo_output_2')(x)
if training:
return Model(inputs, (output_0, output_1, output_2), name='yolov3')
boxes_0 = Lambda(lambda x: yolo_boxes(x, anchors[masks[0]], classes),
name='yolo_boxes_0')(output_0)
boxes_1 = Lambda(lambda x: yolo_boxes(x, anchors[masks[1]], classes),
name='yolo_boxes_1')(output_1)
boxes_2 = Lambda(lambda x: yolo_boxes(x, anchors[masks[2]], classes),
name='yolo_boxes_2')(output_2)
outputs = Lambda(lambda x: nonMaximumSuppression(x, anchors, masks, classes),
name='nonMaximumSuppression')((boxes_0[:3], boxes_1[:3], boxes_2[:3]))
return Model(inputs, outputs, name='yolov3')
Функция потерь с декоратором:
def YoloLoss(anchors, classes=80, ignore_thresh=0.5):
def yolo_loss(y_true, y_pred):
# 1. transform all pred outputs
# y_pred: (batch_size, grid, grid, anchors, (x, y, w, h, obj, ...cls))
pred_box, pred_obj, pred_class, pred_xywh = yolo_boxes(
y_pred, anchors, classes)
pred_xy = pred_xywh[..., 0:2]
pred_wh = pred_xywh[..., 2:4]
# 2. transform all true outputs
# y_true: (batch_size, grid, grid, anchors, (x1, y1, x2, y2, obj, cls))
true_box, true_obj, true_class_idx = tf.split(
y_true, (4, 1, 1), axis=-1)
true_xy = (true_box[..., 0:2] + true_box[..., 2:4]) / 2
true_wh = true_box[..., 2:4] - true_box[..., 0:2]
# give higher weights to small boxes
box_loss_scale = 2 - true_wh[..., 0] * true_wh[..., 1]
# 3. inverting the pred box equations
grid_size = tf.shape(y_true)[1]
grid = tf.meshgrid(tf.range(grid_size), tf.range(grid_size))
grid = tf.expand_dims(tf.stack(grid, axis=-1), axis=2)
true_xy = true_xy * tf.cast(grid_size, tf.float32) - \
tf.cast(grid, tf.float32)
true_wh = tf.math.log(true_wh / anchors)
true_wh = tf.where(tf.math.is_inf(true_wh),
tf.zeros_like(true_wh), true_wh)
# 4. calculate all masks
obj_mask = tf.squeeze(true_obj, -1)
# ignore false positive when iou is over threshold
true_box_flat = tf.boolean_mask(true_box, tf.cast(obj_mask, tf.bool))
best_iou = tf.reduce_max(broadcast_iou(
pred_box, true_box_flat), axis=-1)
ignore_mask = tf.cast(best_iou < ignore_thresh, tf.float32)
# 5. calculate all losses
xy_loss = obj_mask * box_loss_scale * \
tf.reduce_sum(tf.square(true_xy - pred_xy), axis=-1)
wh_loss = obj_mask * box_loss_scale * \
tf.reduce_sum(tf.square(true_wh - pred_wh), axis=-1)
obj_loss = binary_crossentropy(true_obj, pred_obj)
obj_loss = obj_mask * obj_loss + \
(1 - obj_mask) * ignore_mask * obj_loss
# TODO: use binary_crossentropy instead
class_loss = obj_mask * sparse_categorical_crossentropy(
true_class_idx, pred_class)
# 6. sum over (batch, gridx, gridy, anchors) => (batch, 1)
xy_loss = tf.reduce_sum(xy_loss, axis=(1, 2, 3))
wh_loss = tf.reduce_sum(wh_loss, axis=(1, 2, 3))
obj_loss = tf.reduce_sum(obj_loss, axis=(1, 2, 3))
class_loss = tf.reduce_sum(class_loss, axis=(1, 2, 3))
return xy_loss + wh_loss + obj_loss + class_loss
return yolo_loss
Следующая функция трансформирует целевые выводы к кортежу (tuple) следующей формы:
Здесь N – количество меток в пакете (batch), а 6 представляет [x, y, w, h, obj, class] содержащих рамок.
@tf.function
def transform_targets_for_output(y_true, grid_size, anchor_idxs, classes):
N = tf.shape(y_true)[0]
y_true_out = tf.zeros(
(N, grid_size, grid_size, tf.shape(anchor_idxs)[0], 6))
anchor_idxs = tf.cast(anchor_idxs, tf.int32)
indexes = tf.TensorArray(tf.int32, 1, dynamic_size=True)
updates = tf.TensorArray(tf.float32, 1, dynamic_size=True)
idx = 0
for i in tf.range(N):
for j in tf.range(tf.shape(y_true)[1]):
if tf.equal(y_true[i][j][2], 0):
continue
anchor_eq = tf.equal(
anchor_idxs, tf.cast(y_true[i][j][5], tf.int32))
if tf.reduce_any(anchor_eq):
box = y_true[i][j][0:4]
box_xy = (y_true[i][j][0:2] + y_true[i][j][2:4]) / 2
anchor_idx = tf.cast(tf.where(anchor_eq), tf.int32)
grid_xy = tf.cast(box_xy // (1/grid_size), tf.int32)
indexes = indexes.write(
idx, [i, grid_xy[1], grid_xy[0], anchor_idx[0][0]])
updates = updates.write(
idx, [box[0], box[1], box[2], box[3], 1, y_true[i][j][4]])
idx += 1
return tf.tensor_scatter_nd_update(
y_true_out, indexes.stack(), updates.stack())
def transform_targets(y_train, anchors, anchor_masks, classes):
outputs = []
grid_size = 13
anchors = tf.cast(anchors, tf.float32)
anchor_area = anchors[..., 0] * anchors[..., 1]
box_wh = y_train[..., 2:4] - y_train[..., 0:2]
box_wh = tf.tile(tf.expand_dims(box_wh, -2),
(1, 1, tf.shape(anchors)[0], 1))
box_area = box_wh[..., 0] * box_wh[..., 1]
intersection = tf.minimum(box_wh[..., 0], anchors[..., 0]) * \
tf.minimum(box_wh[..., 1], anchors[..., 1])
iou = intersection / (box_area + anchor_area - intersection)
anchor_idx = tf.cast(tf.argmax(iou, axis=-1), tf.float32)
anchor_idx = tf.expand_dims(anchor_idx, axis=-1)
y_train = tf.concat([y_train, anchor_idx], axis=-1)
for anchor_idxs in anchor_masks:
outputs.append(transform_targets_for_output(
y_train, grid_size, anchor_idxs, classes))
grid_size *= 2
return tuple(outputs) # [x, y, w, h, obj, class]
def preprocess_image(x_train, size):
return (tf.image.resize(x_train, (size, size))) / 255
Теперь мы создаем экземпляр нашей модели, загружаем веса и имена классов. В датасете COCO их 80.
yolo = YoloV3(classes=num_classes) load_darknet_weights(yolo, weightsyolov3) yolo.save_weights(checkpoints) class_names = ["person", "bicycle", "car", "motorbike", "aeroplane", "bus", "train", "truck", "boat", "traffic light", "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana","apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake","chair", "sofa", "pottedplant", "bed", "diningtable", "toilet", "tvmonitor", "laptop", "mouse","remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink", "refrigerator","book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush"]
Вот и все! Прямо сейчас мы можем запустить и протестировать нашу модель на каком-нибудь изображении.
name = 'detect.jpg'
img = tf.image.decode_image(open(name, 'rb').read(), channels=3)
img = tf.expand_dims(img, 0)
img = preprocess_image(img, size)
boxes, scores, classes, nums = yolo(img) #eager mode
img = cv2.imread(name)
img = draw_outputs(img, (boxes, scores, classes, nums), class_names)
cv2.imwrite('output.jpg', img)
После выполнения этого кода в файле output.jpg окажется то же изображение с рамками, отмечающими объекты, распознанные нашей нейронной сетью:
Распознавание видео с камеры
Мы уже добились впечатляющего результата, но главное еще впереди! Самое важное в архитектуре YOLO не то, что она довольно неплохо умеет распознавать объекты, а то, что она делает это быстро. Настолько быстро, что успевает обработать все кадры, поступающие от веб-камеры. Включите веб-камеру и запустите следующий код:
cap = cv2.VideoCapture(0)
while(True):
# Capture frame-by-frame
ret, frame = cap.read()
# Our operations on the frame come here
#img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
img = tf.expand_dims(frame, 0)
img = preprocess_image(img, size)
boxes, scores, classes, nums = yolo(img) #eager mode
img = draw_outputs(frame, (boxes, scores, classes, nums), class_names)
# Display the resulting frame
cv2.imshow('frame',img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything done, release the capture
cap.release()
cv2.destroyAllWindows()
Вы увидите на экране изменяющуюся картинку с камеры, на которой будут отмечены все распознанные объекты. Теперь вы можете перемещать свою камеру или двигать объекты в кадре, и нейронная сеть будет успевать обрабатывать меняющиеся изображения.
Желаю удачных и забавных экспериментов с YOLO!
Ссылки: