

Ограничение NOT NULL
В этом примере оба столбца описаны с ограничением NOT NULL. Оно говорит о том, что значение в этом столбце не может быть пустым. При добавлении новой записи все столбцы, имеющие ограничение NOT NULL, должны содержать какое-то значение. Остальные могут оставаться пустыми, если нам нечего в них ввести.
Если в столбце разрешены пустые значения (NULL) мы можем либо совсем ничего не указывать при описании столбца, либо явно указать NULL. Некоторые СУБД, например DB2, не поддерживают ключевое слово NULL, поэтому просто ничего не указывайте.
Первичные ключи
При описании таблицы мы назначили столбец PetTypeId первичным ключом (primary key). Первичный ключ – это один или несколько столбцов, по которым мы можем однозначно отличить одну запись в нашей таблице от другой. Чтобы показать, какие столбцы мы назначили первичным ключом, мы должны использовать ограничение PRIMARY KEY в каждом из них. Если вдруг забыли указать первичный ключ при создании таблицы с помощью оператора CREATE TABLE, его можно указать позже, использовав оператор ALTER TABLE для изменения описания таблицы.
Первичный ключ должен содержать только уникальные значения, такие значения не могут повторяться в разных записях. Значения могут быть простые, как, например целые числа с автоматическим увеличением (автоинкрементом) или артикулы товаров (вроде pr4650, pr2784, pr5981 и т. п.). И конечно, первичный ключ всегда должен содержать значение, он не может быть NULL.
Хотя первичный ключ и не является обязательным, считается хорошей практикой указывать первичный ключ в каждой таблице.
Создаем другие таблицы
Давайте создадим еще две таблицы:
CREATE TABLE Owners
(
OwnerId int NOT NULL PRIMARY KEY,
FirstName varchar(60) NOT NULL,
LastName varchar(60) NOT NULL,
Phone varchar(20) NOT NULL,
Email varchar(254)
);
CREATE TABLE Pets
(
PetId int NOT NULL PRIMARY KEY,
PetTypeId int NOT NULL REFERENCES PetTypes (PetTypeId),
OwnerId int NOT NULL REFERENCES Owners (OwnerId),
PetName varchar(60) NOT NULL,
DOB date NULL
);
Они обе похожи на первую, только содержат больше столбцов и в них можно заметить пару новых моментов.
Отношения
Когда мы создали таблицу Pets, мы на самом деле еще и создали отношения (англ.) между тремя таблицами. Эти отношения показаны на диаграмме ниже.
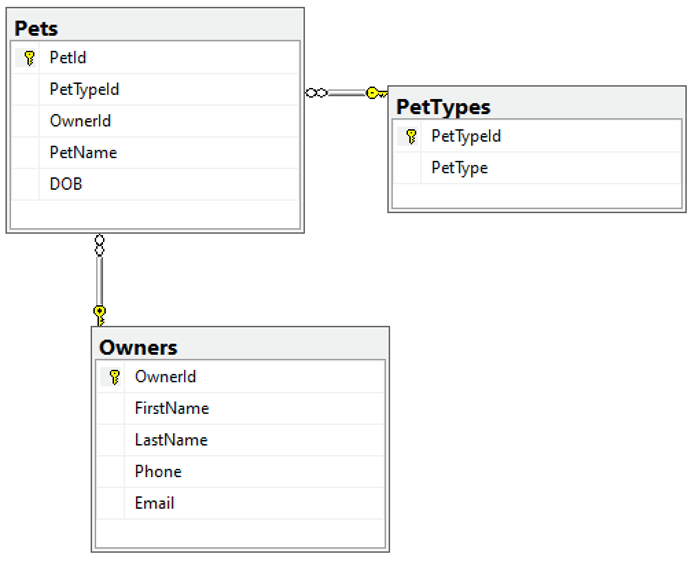
Отношения внутри баз данных являются важной частью SQL. Они позволяют нам запрашивать взаимосвязанные данные из нескольких таблиц и получать точные и согласованные результаты. В нашем случае мы хотим иметь возможность получать данные о питомцах по их владельцам, по видам питомцев и т. д. И хотим, чтобы полученные результаты были правильными и согласованными между собой.
Чтобы достичь такого, нам нужно, чтобы записи о питомце были введены с указанием их владельца и вида питомца. Значит, когда мы добавляем в таблицу Pets запись о питомце, мы должны убедиться, что ей соответствуют записи о владельце в таблице Owners (владельцы) и виде питомца в таблице PetTypes.
У нас будут следующие требования:
- Любое значение в столбце
PеtTypeIdтаблицыPetsдолжно соответствовать какому-то значению в столбцеPеtTypeIdтаблицыPetTypes. - Любое значение в столбце
OwnerIdтаблицыPetsдолжно соответствовать какому-то значению в столбцеOwnerIdтаблицыOwners.
Мы можем обеспечить выполнение этих требований, указав внешние ключи (foreign keys, англ.) в соответствующих столбцах таблицы Pets. Ограничение вторичного ключа используется, чтобы указать, что значения в этом столбце связаны со значениями первичного ключа в другой таблице. Приведенный выше код для создания таблицы Pets фактически создает два внешних ключа.
Обратите внимание, что описания столбцов PetTypeId и OwnerId содержат новый для нас код, который начинается со слова REFERENCES. Именно этот код и создает вторичные ключи.
Когда мы создавали таблицу Pets, в столбце PetTypeId мы добавили конструкцию REFERENCES PetTypes (PetTypeId). Она означает, что столбец PetTypeId в этой таблице ссылается на значения из столбца PetTypeId в таблице PetTypes. То же самое мы сделали и в столбце OwnerId, который теперь ссылается на значения из одноименного столбца в таблице.
В большинстве СУБД вторичные ключи можно создавать в уже существующих таблицах, используя оператор ALTER TABLE, но мы сейчас не будем останавливаться на этом.
Так или иначе, мы создали связи между таблицами и теперь при добавлении записей в таблицу Pets нам нужно, чтобы значения в столбцах PetTypeId и OwnerId содержали одно из значений, существующих в одноименных столбцах таблиц PetTypes и Owners. В противном случае СУБД вернет нам ошибку.
Это одно из преимуществ вторичных ключей. Они помогают нам избежать добавления некорректных данных или, говоря иначе, поддерживать целостность данных (англ.) в нашей базе, а именно ссылочную целостность (англ.).
Ограничения-проверки
Ограничения-проверки – это еще один вид ограничений, о котором вам нужно знать. Такие ограничения проверяют данные, прежде чем вы сохраните их в базе данных. Когда в таблице включено ограничение-проверка, данные могут попасть в таблицу только в том случае, если они не нарушают такое ограничение. Данные, нарушающие ограничение, не будут записаны.
Например, мы могли бы создать ограничение-проверку для столбца цены, чтобы гарантировать, что он принимает только значения, которые больше нуля. Или мы могли бы применить ограничение-проверку к нашей таблице Pets, чтобы гарантировать, что в столбец DOB (day of birth – день рождения, прим. перев.) не будет записан день рождения больше текущей даты.
Пробелы и отступы
Возможно, вы заметили, что в моих примерах присутствуют пробелы. Например, я разделил код на несколько строк и использовал табуляции для отступов при указании типов данных и т. д. Это вполне допустимо в SQL. Вы можете спокойно добавлять пробелы и отступы, и это никак не повлияет на результат. SQL позволяет вам разделить ваш код на несколько строк, если вам так удобнее, и позволяет использовать отступы из нескольких пробелов или табуляций для повышения удобочитаемости.
Комментарии
Вы также можете включать комментарии в свой код. Комментарии могут пригодиться, когда вы начнете писать более длинные SQL-скрипты. Как только сценарий становится довольно длинным, комментарии помогут быстрее понять, что делает каждая часть кода.
Строчные комментарии
Комментарии можно включать внутрь своего кода. Такой комментарий называется строчными и начинается с двух символов дефиса (--):
SELECT * FROM Pets; -- Это комментарий
-- Это тоже комментарий
SELECT * FROM Owners;
Блочные комментарии
Можно вставлять комментарии, состоящие из нескольких строк. Такой комментарий начинается с пары символов /* и завершается другой парой */:
/*
Это более длинный комментарий,
состоящий из четырех строк
*/
SELECT * FROM Pets;
Блочные комментарии СУБД тоже игнорирует при выполнении скрипта.
Особенности MySQL
Если вы работаете с MySQL, то помимо двух дефисов (--) для строчных комментариев можно также использовать символ решетки (#):
# Это комментарий для MySQL
SELECT * FROM Pets;
Комментирование кода
Удобным приемом при разработке является возможность закомментировать код. Например, если вы создаете длинный скрипт, который делает много всего, но для проверки хотите запустить только какую-то часть своего кода, вы можете закомментировать остальные части.
-- SELECT * FROM Pets;
SELECT * FROM Owners;
В таком случае первый оператор SELECT не будет выполняться, т. к. он превращен в комментарий – закомментирован. Выполнится только второй оператор SELECT. Когда нужно закомментировать большой фрагмент кода, можно смело использовать блочный комментарий.
Заполнение данными
Мы создали три таблицы, добавили в них подходящие внешние ключи и пришло время ввести данные. Чаще всего в SQL для этого используются операторы INSERT. Выглядит это примерно так:
INSERT INTO МояТаблица(Столбец, Столбец2, Столбец3, ...)
VALUES(Значение1, Значение 2, Значение 3, ...);
Нам нужно только заменить имя МояТаблица на имя таблицы, в которую мы будем добавлять запись. Точно так же нужно будет заменить Столбец1,… на имена столбцов, а Значение1,… – на данные, которые вы хотите записать в соответствующие столбцы записи. Например, вот так:
INSERT INTO Pets(PetId, PetTypeId, OwnerId, PetName, DOB)
VALUES(1, 2, 3, 'Fluffy', '2020-12-20');
Значения должны быть указаны в том же порядке, в котором были указаны столбцы. Обратите внимание, что имена столбцов в операторе INSERT в точности совпадают с именами, которые мы указали при создании таблицы.
Мы можем опустить имена столбцов, если мы заполняем их все. Давайте упростим наш пример:
INSERT INTO Pets
VALUES(1, 2, 3, 'Fluffy', '2020-12-20');
Чтобы заниматься изучением SQL дальше, давайте добавим побольше записей в наши таблицы, вставляя каждую из них с помощью отдельного оператора INSERT.
INSERT INTO Owners(OwnerId, FirstName, LastName, Phone, Email)
VALUES(1, 'Homer', 'Connery', '(308) 555-0100', '[email protected]');
INSERT INTO Owners(OwnerId, FirstName, LastName, Phone, Email)
VALUES(2, 'Bart', 'Pitt', '(231) 465-3497', '[email protected]' );
INSERT INTO Owners(OwnerId, FirstName, LastName, Phone)
VALUES(3, 'Nancy', 'Simpson', '(489) 591-0408');
INSERT INTO Owners(OwnerId, FirstName, LastName, Phone)
VALUES(4, 'Boris', 'Trump', '(349) 611-8908');
INSERT INTO PetTypes(PetTypeId, PetType)
VALUES(1, 'Bird');
INSERT INTO PetTypes(PetTypeId, PetType)
VALUES(2, 'Cat');
INSERT INTO PetTypes(PetTypeId, PetType)
VALUES(3, 'Dog');
INSERT INTO PetTypes(PetTypeId, PetType)
VALUES(4, 'Rabbit');
INSERT INTO Pets(PetId, PetTypeId, OwnerId, PetName, DOB)
VALUES(1, 2, 3, 'Fluffy', '2020-11-20');
INSERT INTO Pets(PetId, PetTypeId, OwnerId, PetName, DOB)
VALUES(2, 3, 3, 'Fetch', '2019-08-16');
INSERT INTO Pets(PetId, PetTypeId, OwnerId, PetName, DOB)
VALUES(3, 2, 2, 'Scratch', '2018-10-01');
INSERT INTO Pets(PetId, PetTypeId, OwnerId, PetName, DOB)
VALUES(4, 3, 3, 'Wag', '2020-03-15');
INSERT INTO Pets(PetId, PetTypeId, OwnerId, PetName, DOB)
VALUES(5, 1, 1, 'Tweet', '2020-11-28');
INSERT INTO Pets(PetId, PetTypeId, OwnerId, PetName, DOB)
VALUES(6, 3, 4, 'Fluffy', '2020-09-17');
INSERT INTO Pets(PetId, PetTypeId, OwnerId, PetName)
VALUES(7, 3, 2, 'Bark');
INSERT INTO Pets(PetId, PetTypeId, OwnerId, PetName)
VALUES(8, 2, 4, 'Meow');
Обратите внимание, что таблицу Pets мы заполнили последней. Для этого есть причина. Если бы мы попытались добавить записи в таблицу Pets перед заполнением двух других, мы бы получили сообщение об ошибке из-за нашего ограничения внешнего ключа. И это правильно. Ведь мы бы пытались добавить значения в столбцы внешних ключей, которые еще не существуют в первичных ключах связанных таблиц. Но подобное нельзя делать, когда у нас определены вторичные ключи. Заполнив таблицы Owners и PetTypes первыми, мы позаботились о том, чтобы подходящие значения существовали в первичных ключах, прежде чем мы их стали использовать при заполнении таблицы Pets.
Проверим наши данные
Ну вот, теперь мы можем выполнять запросы к нашей базе данных. Давайте проверим все наши таблицы.
SELECT * FROM Pets;
SELECT * FROM PetTypes;
SELECT * FROM Owners;
Результат:
+---------+-------------+-----------+-----------+------------+
| PetId | PetTypeId | OwnerId | PetName | DOB |
|---------+-------------+-----------+-----------+------------|
| 1 | 2 | 3 | Fluffy | 2020-11-20 |
| 2 | 3 | 3 | Fetch | 2019-08-16 |
| 3 | 2 | 2 | Scratch | 2018-10-01 |
| 4 | 3 | 3 | Wag | 2020-03-15 |
| 5 | 1 | 1 | Tweet | 2020-11-28 |
| 6 | 3 | 4 | Fluffy | 2020-09-17 |
| 7 | 3 | 2 | Bark | NULL |
| 8 | 2 | 4 | Meow | NULL |
+---------+-------------+-----------+-----------+------------+
(8 rows affected)
+-------------+-----------+
| PetTypeId | PetType |
|-------------+-----------|
| 1 | Bird |
| 2 | Cat |
| 3 | Dog |
| 4 | Rabbit |
+-------------+-----------+
(4 rows affected)
+-----------+-------------+------------+----------------+-------------------+
| OwnerId | FirstName | LastName | Phone | Email |
|-----------+-------------+------------+----------------+-------------------|
| 1 | Homer | Connery | (308) 555-0100 | [[email protected]](<mailto:[email protected]>) |
| 2 | Bart | Pitt | (231) 465-3497 | [[email protected]](<mailto:[email protected]>) |
| 3 | Nancy | Simpson | (489) 591-0408 | NULL |
| 4 | Boris | Trump | (349) 611-8908 | NULL |
+-----------+-------------+------------+----------------+-------------------+
(4 rows affected)
Отлично, все данные выглядят именно так, как мы их и добавляли.
Выбираем данные из отдельных столбцов
Обычно считается плохой практикой выбирать все строки и все столбцы из таблицы (как мы это сделали в предыдущем примере) без крайней на то необходимости. Такой запрос может повлиять на производительность вашего сервера базы данных, особенно если в таблице много строк.
Полная выборка не представляет проблем, когда вы используете небольшие наборы данных, как мы сейчас. В противном случае, как правило, лучше выбрать только те столбцы, которые вам нужны. Например, если бы нам нужны были только идентификаторы, имена и даты рождения всех домашних животных, мы могли бы сделать это:
SELECT PetId, PetName, DOB
FROM Pets;
Результат:
+---------+-----------+------------+
| PetId | PetName | DOB |
|---------+-----------+------------|
| 1 | Fluffy | 2020-11-20 |
| 2 | Fetch | 2019-08-16 |
| 3 | Scratch | 2018-10-01 |
| 4 | Wag | 2020-03-15 |
| 5 | Tweet | 2020-11-28 |
| 6 | Fluffy | 2020-09-17 |
| 7 | Bark | NULL |
| 8 | Meow | NULL |
+---------+-----------+------------+
Если бы нам нужны были идентификаторы и даты рождения всех домашних животных по имени Fluffy, мы могли бы сделать это так:
SELECT PetId, DOB
FROM Pets
WHERE PetName = 'Fluffy';
Результат:
+---------+------------+
| PetId | DOB |
|---------+------------|
| 1 | 2020-11-20 |
| 6 | 2020-09-17 |
+---------+------------+
Вы также можете использовать оператор SELECT для получения данных, которые не хранятся в таблице. Например, текущей даты и времени.
Сортировка
Для сортировки данных в языке SQL используется предложение ORDER BY. Мы можем добавить его к нашему предыдущему запросу, чтобы вывести имена питомцев в алфавитном порядке:
SELECT PetId, PetName, DOB
FROM Pets
ORDER BY PetName ASC;
Результат:
+---------+-----------+------------+
| PetId | PetName | DOB |
|---------+-----------+------------|
| 7 | Bark | NULL |
| 2 | Fetch | 2019-08-16 |
| 1 | Fluffy | 2020-11-20 |
| 6 | Fluffy | 2020-09-17 |
| 8 | Meow | NULL |
| 3 | Scratch | 2018-10-01 |
| 5 | Tweet | 2020-11-28 |
| 4 | Wag | 2020-03-15 |
+---------+-----------+------------+
Сокращение ASC означает ascending (по возрастанию). По умолчанию (без указания направления) сортировка всегда производится по возрастанию, поэтому указывать ASC не обязательно. Чтобы отсортировать по убыванию, используется сокращение DESC (descending).
SELECT PetId, PetName, DOB
FROM Pets
ORDER BY PetName DESC;
Результат:
+---------+-----------+------------+
| PetId | PetName | DOB |
|---------+-----------+------------|
| 4 | Wag | 2020-03-15 |
| 5 | Tweet | 2020-11-28 |
| 3 | Scratch | 2018-10-01 |
| 8 | Meow | NULL |
| 1 | Fluffy | 2020-11-20 |
| 6 | Fluffy | 2020-09-17 |
| 2 | Fetch | 2019-08-16 |
| 7 | Bark | NULL |
+---------+-----------+------------+
Мы можем также отсортировать результат по нескольким столбцам. При этом сначала производится сортировка по столбцу, указанному первым, затем по столбцу, указанному вторым, и так далее.
SELECT PetId, PetName, DOB
FROM Pets
ORDER BY PetName DESC, DOB;
Результат:
+---------+-----------+------------+
| PetId | PetName | DOB |
|---------+-----------+------------|
| 4 | Wag | 2020-03-15 |
| 5 | Tweet | 2020-11-28 |
| 3 | Scratch | 2018-10-01 |
| 8 | Meow | NULL |
| 6 | Fluffy | 2020-09-17 |
| 1 | Fluffy | 2020-11-20 |
| 2 | Fetch | 2019-08-16 |
| 7 | Bark | NULL |
+---------+-----------+------------+
Посмотрите, как две записи с питомцем по имени Fluffy поменялись местами в списке из-за сортировки по дню рождения (DOB – date of birth).
Если вы не используете предложение ORDER BY, нет никакой гарантии, в каком порядке будут располагаться ваши результаты. Хотя может показаться, что ваша база данных сортирует результаты по определенному столбцу, на самом деле это может быть не так. В общем, без предложения ORDER BY данные будут отсортированы в том порядке, в котором они были загружены в таблицу. Однако, если записи были удалены или изменены, порядок будет зависеть от того, как СУБД повторно использует освобожденное место для добавления новых данных. Поэтому не полагайтесь на СУБД для сортировки результатов в каком-либо значимом порядке.
Вывод: если вы хотите обеспечить всегда одинаковый порядок результатов, используйте предложение ORDER BY.
Комментарии