

IPC (межпроцессное взаимодействие) часто не учитывается при оптимизации затрат в облачных средах. Но оказывается, что если вы будете передавать 1 Тб видео в секунду на облачном сервисе типа AWS, это может привести к огромным счетам: компания Recall.ai обнаружила, что использование WebSockets через loopback-интерфейс обходилось в дополнительный $1 млн в год. Для снижения расходов разработчикам срочно нужно было найти более эффективный способ обмена данными – с максимально высокой пропускной способностью и низкой задержкой.
Кейс
Компания Recall.ai предоставляет услуги видеопереработки и записи встреч. Нагрузка огромная: ботами Recall.ai пользуются сотни компаний, инфраструктура обрабатывает миллионы видеоконференций в месяц. Для обработки видео компания использует CPU, а не GPU, поскольку облачные провайдеры (даже AWS) не всегда могут предложить стабильный доступ к GPU в нужных масштабах. В результате все задачи – от запуска браузера до обработки видео в реальном времени – выполняются на CPU. Перед разработчиками поставили непростую цель – сократить потребление ресурсов на каждого бота с 4 ядер CPU до 2, тем самым уменьшив счета на облачные вычисления вдвое. Для реализации этой цели нужно было:
- Выполнить профилирование – проанализировать, как работают боты, и выявить самые ресурсоемкие процессы.
- Снизить нагрузку на CPU без ущерба для производительности.
Неожиданные результаты профилирования
До анализа производительности ботов разработчики ожидали, что основная часть ресурсов процессора тратится на кодирование и декодирование видео: как известно, обработка видео – очень затратный процесс. Однако профилирование показало совершенно неожиданное: большая часть процессорного времени тратилoсь на функции __memmove_avx_unaligned_erms и __memcpy_avx_unaligned_erms. Эти функции принадлежат стандартной библиотеке C (glibc) и отвечают за быстрое копирование данных в памяти. Основными виновниками вызовов были:
- Клиент WebSocket на Python, который принимал данные.
- Реализация WebSocket в Chromium, которая отправляла данные.
Иными словами, передача данных через WebSocket приводила к огромному числу операций копирования в памяти.
Почему WebSocket оказался медленным
Чтобы понять, почему WebSocket использует так много ресурсов CPU, разработчики начали с анализа своего подхода. Их система взаимодействует с безголовым Chromium, который обеспечивает интерфейс для видеозвонков. Изначально WebSocket был выбран для передачи декодированного видео из Javascript-среды в энкодер по нескольким причинам:
- Скорость – WebSocket быстрее большинства других веб-API.
- Доступность – легко использовать в среде Javascript.
- Поддержка бинарных данных – WebSocket может передавать не только текст, но и двоичные данные.
- Интеграция в Chromium, не требующая дополнительных зависимостей.
Однако разработчики не учли один нюанс – огромный объем данных. Для каждого видеопотока в 1080p с частотой 30 кадров в секунду объем составлял 1080 × 1920 × 1,5 ×30 = 93,312 Мб/с. С учетом масштабирования системы (p99 бот, т. е. 99-й перцентиль нагрузки), поток достигал 150 Мб/с – и весь этот объем постоянно передавался между процессами.
Причины высокой нагрузки на WebSocket
После изучения стандартов WebSocket (RFC) и реализации в Chromium, команда нашла два ключевых фактора, замедляющих передачу данных – ими оказались фрагментация и маскирование.
Фрагментация
Это процесс разбивки больших сообщений на несколько частей (фреймов WebSocket). Фрагментация позволяет отправлять данные частями, даже если их общий размер заранее неизвестен, и помогает в случаях, когда одно большое сообщение не должно монополизировать канал связи. В реализации WebSocket в Chromium любое сообщение больше 131 Кб разбивается на отдельные фрагменты:
1080 × 1920 × 1,5 = 3110,4 Кб / 131 = 24 WebSocket-фрейма.
То есть каждый кадр видео разбивается на 24 фрагмента, и при обработке каждого из них выполняется много лишних операций – создание заголовков, перемещение данных в памяти и управление соединением.
Маскирование
По спецификации WebSocket, все данные, отправляемые от клиента к серверу, должны быть замаскированы. Это обязательное требование введено для безопасности и для предотвращения проблем с сетевыми посредниками (например, прокси-серверами). Маскирование заключается в следующем:
- Клиент генерирует случайный 32-битный ключ маскирования.
- Затем каждый байт исходных данных XOR-ится с этим ключом:
- Данные разбиваются на 32-битные блоки (4 байта).
- Каждый блок обрабатывается с использованием ключа.
- Результат этой операции отправляется на сервер.
Хотя маскирование важно для безопасности, оно создает дополнительную нагрузку на CPU – XOR-проходка по всем данным незначительна для обычных веб-приложений, где объем данных сравнительно небольшой, но при передаче больших объемов (например, 100+ Мб/с, как в случае с видео) такие дополнительные операции становятся заметной нагрузкой.
Разработка более эффективного способа передачи данных
После того как стало ясно, что WebSocket для передачи данных слишком ресурсоемок, команда решила искать альтернативу для извлечения данных из Chromium. Однако стандартные браузерные API оказались слишком ограниченными для реализации чего-то более производительного, чем WebSocket. Поэтому было принято решение форкнуть Chromium и реализовать собственный метод обмена данными. В качестве базы для этого решения команда рассмотрела три варианта: TCP/IP, сокеты домена Unix и общую память.
TCP/IP
Плюсы:
- Обход ограничений WebSocket – данные передаются напрямую через пакетный протокол.
- Низкая задержка – использование loopback (виртуального сетевого интерфейса) минимизирует время ожидания.
Минусы:
- Фрагментация пакетов. Максимальный размер пакета TCP/IP (MSS) на стандартной сети Ethernet – 1448 байт. Это значительно меньше размера одного кадра видео в 3 Мб. Даже теоретический максимум TCP/IP – целых 64 Кб – все равно недостаточен, что приводит к фрагментации.
- Копирование данных. Пакеты передаются через сетевой стек Linux, который работает в kernel-space. Данные нужно копировать из user-space в kernel-space, что добавляет накладные расходы, особенно при передаче больших объемов данных.
Сокеты домена Unix
Плюсы:
- Низкие накладные расходы – IPC-сокеты быстрее TCP/IP, так как они обходят сетевой стек.
- Нативная поддержка в Linux. Это стандартная технология для IPC (взаимодействия между процессами), поддерживаемая Linux, с библиотеками и функциями для передачи данных.
Минус:
- Копирование данных. Как и в случае с TCP/IP, данные копируются из user-space в kernel-space и обратно. Для объемов в 100+ Мб/с это все еще серьезная нагрузка.
Общая память (Shared Memory)
Плюсы:
- Максимальная производительность. Общая память позволяет нескольким процессам одновременно обращаться к одному и тому же блоку памяти. Chromium может записывать данные в память, а видеокодер считывать их напрямую, без копирования.
- Отсутствие накладных расходов kernel-space. Все операции происходят в user-space, что минимизирует задержки и нагрузку.
Минусы:
Нет стандартного интерфейса. В отличие от TCP/IP или IPC-сокетов, у общей памяти нет готового стандарта для передачи данных. Это означает, что:
- Нужно разрабатывать все с нуля.
- Есть риск допустить ошибки в реализации.
- Требуется больше усилий на поддержку.
Взвесив все плюсы и минусы, команда пришла к выводу, что для решения их задачи общая память станет лучшим вариантом. Хотя реализация этого метода требовала много усилий, необходимость снижения расходов стала отличной мотивацией.
Использование кольцевого буфера для оптимизации передачи данных
Для эффективного чтения и записи данных в общую память команда решила использовать кольцевой буфер как основу транспортного механизма. Требования были такими:
- Без блокировок – для минимизации задержек и стабильной обработки в реальном времени. Любая блокировка могла бы нарушить работу видеопотока.
- Поддержка нескольких производителей и одного потребителя (MPSC). Несколько потоков Chromium записывают аудио- и видеоданные в буфер, а один поток медиа-конвейера обрабатывает эти данные.
- Динамические размеры кадров. Буфер должен поддерживать обработку видеокадров с разными разрешениями.
- Чтение без копирования (zero-copy). Медиа-конвейер должен считывать данные прямо из буфера, избегая лишнего копирования.
- Совместимость с песочницей. Потоки Chromium, работающие в песочнице, должны иметь легкий доступ к буферу.
- Сигналы с низкой задержкой. Буфер должен уведомлять потоки Chromium, когда есть свободное место, и медиа-конвейер, когда появились новые данные.
Однако существующие реализации кольцевого буфера не подходили под специфические требования проекта, – пришлось разрабатывать собственный буфер.
Кастомный кольцевой буфер
Стандартные кольцевые буферы используют два указателя:
- write pointer (aдрес, куда будут записываться новые данные)
- read pointer (aдрес, где данные можно перезаписать).
Для поддержки чтения без копирования был добавлен третий указатель – peek pointer. Это адрес, с которого медиа-конвейер начинает читать кадры.
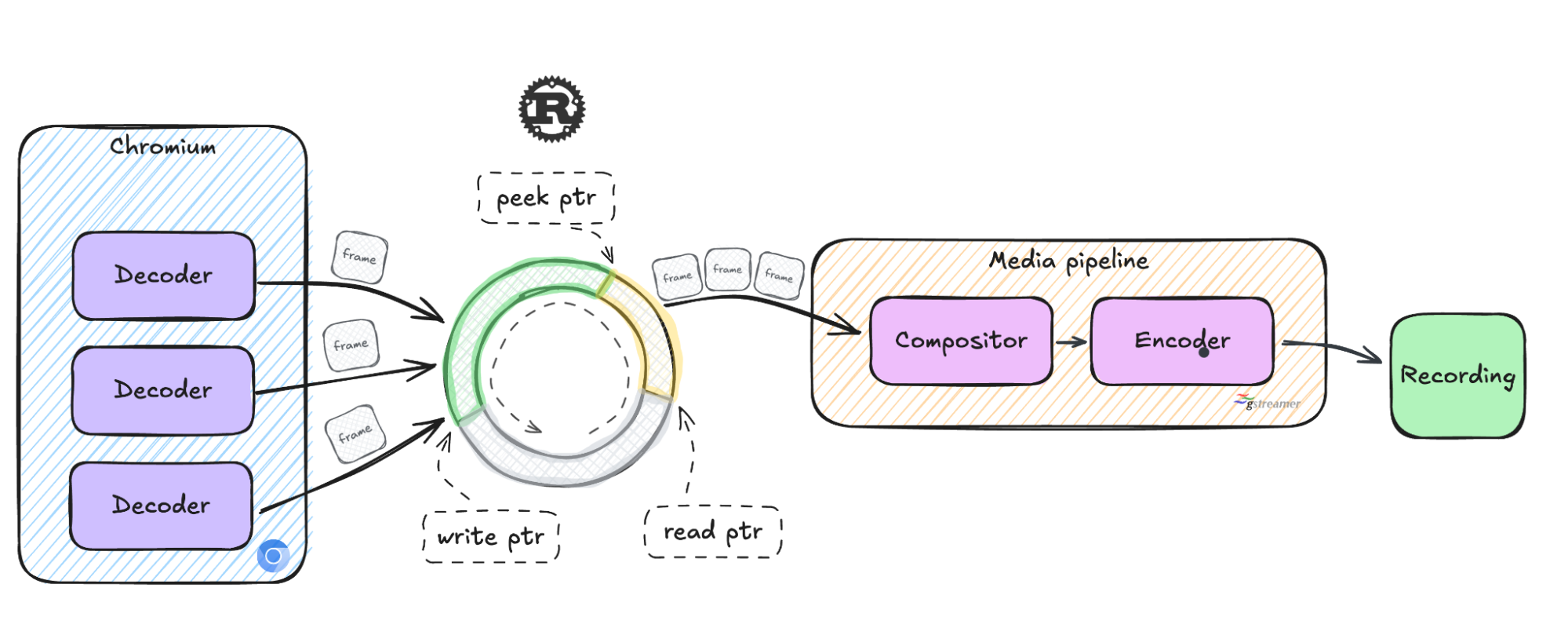
Особенности кастомной реализации буфера:
- Чтение без копирования:
- Медиа-конвейер считывает данные с помощью peek pointer.
- Данные остаются валидными до тех пор, пока они полностью не обработаны.
- Только после обработки указатель read pointer продвигается вперед, что освобождает место в буфере.
- Потокобезопасность – для обновления указателей используются атомарные операции.
- Семафоры – для сигнализации между потоками используется семафор – Chromium уведомляет, когда записаны новые данные, а медиа-конвейер сигнализирует, когда освободилось место в буфере.
Итоги
Разработка собственного кольцевого буфера позволила добиться повышения производительности при уменьшении затрат:
- Использование CPU удалось снизить на 50%.
- Значительно повысилась производительность ботов.
Оптимизация привела к снижению годовых расходов более чем на $1 млн.
Есть ли у вас опыт работы с альтернативными методами передачи данных? Поделитесь своими находками в комментариях!
Комментарии