
Прогнозирование численности населения
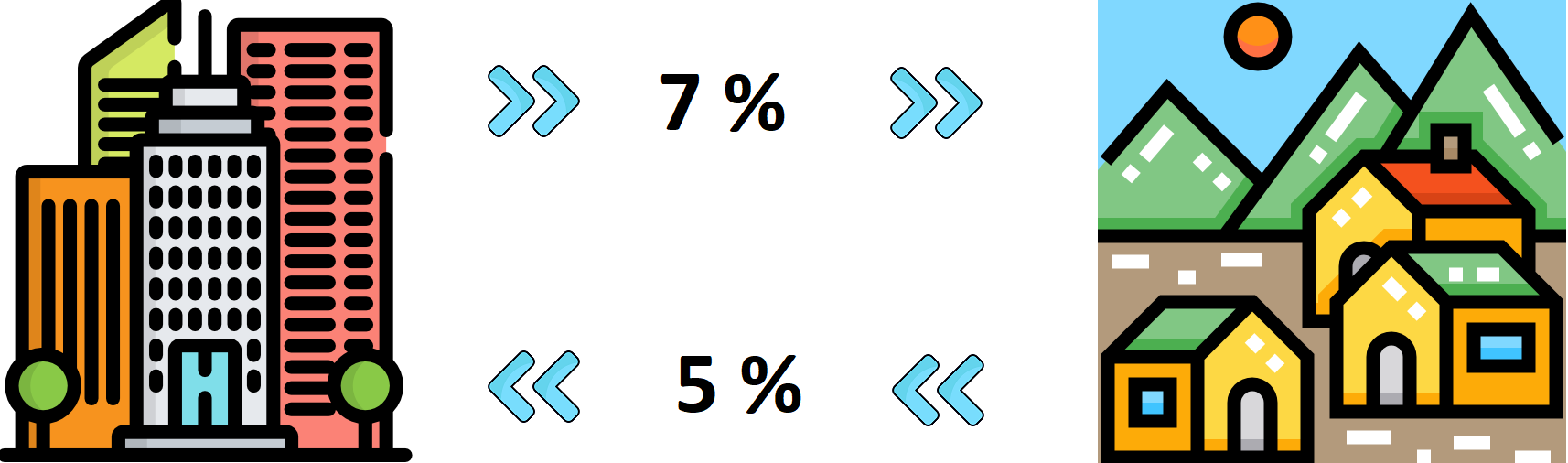
В одном регионе примерно 7% городского населения ежегодно переезжает из города в ближайшие пригороды, а 5% обитателей пригородов, наоборот, переселяется в город. В 2024 году в городе проживало 800 000 человек, а в пригородах – 500 000.
Оцените численность населения в городе и пригородах через 2 года. Игнорируйте другие факторы, которые в реальной жизни влияют на размер населения.
Решение
Эту задачу можно решить с помощью системы уравнений. Но можно воспользоваться цепью Маркова, поскольку условие описывает все ключевые признаки марковского процесса:
- Два состояния (число жителей в городе S1 и число жителей в пригородах S2) соответствуют дискретным состояниям в цепи Маркова.
- Дискретное время – в задаче рассматриваются переходы по годам, а не непрерывный процесс.
- Вероятности перехода населения из одного состояния в другое можно представить в виде матрицы перехода (например, вероятность того, что житель города останется в городе равна 0,93, а вероятность переезда в пригороды – 0,07).
- Вероятность того, где окажется человек в следующем году, зависит только от текущего распределения и не зависит от того, где он был ранее.
Для нахождения населения через 2 года используется формула X = P2S, где Pn показывает вероятность перехода за n шагов:
import numpy as np
# Начальное население (город, пригороды)
S = np.array([[800000], [500000]])
# Матрица перехода
P = np.array([[0.93, 0.05],
[0.07, 0.95]])
# Вычисляем население через 2 года (P^2 * S)
P2 = np.linalg.matrix_power(P, 2)
X = np.dot(P2, S)
city_population = int(X[0, 0])
suburb_population = int(X[1, 0])
print(f"Население города через 2 года: {city_population}")
print(f"Население пригородов через 2 года: {suburb_population}")
Результат:
Население города через 2 года: 741720
Население пригородов через 2 года: 558280
Вебинар «Математика для ML: от теории к практике»
6 марта в 20:00 (МСК) Мария Горденко, инженер-программист и ведущий эксперт НИУ ВШЭ, проведет интенсивный вебинар по основам математики для машинного обучения.
Что будет на вебинаре:
- Теория вероятностей: случайные величины, математическое ожидание, дисперсия и их применение в Random Forest
- Линейная алгебра: векторы, матрицы, собственные векторы и значения — основа для SVD-разложения и PCA-анализа
- Математический анализ: производные и ряды Тейлора в контексте градиентного бустинга и методов оптимизации
Для кого этот вебинар:
- Начинающих в IT, выбирающих направление развития
- Разработчиков, желающих применить навыки в новой области
- Математиков, стремящихся перейти от теории к практике
- Всех, кто хочет понять математическую основу современных ML-алгоритмов
Регистрация открыта на сайте. Не упустите возможность структурировать свои знания и сделать первый шаг к пониманию математики в машинном обучении.
Минимальная стоимость выполнения работ

Предположим, что у вас есть n задач, которые нужно биективно назначить n работникам (то есть каждому работнику соответствует одна задача, и каждой задаче соответствует один работник). Каждая задача имеет длительность в часах, а каждый работник – стоимость работы в час.
Ваша цель — найти такое распределение задач между работниками, при котором общая сумма оплаты будет минимальной.
Решение
Эта задача сводится к нахождению минимального скалярного произведения двух векторов:
- Нам даны два вектора x (длительность выполнения) и y (стоимость работы за час), состоящие из неотрицательных чисел.
- Нужно найти такую перестановку π, при которой сумма будет минимальной:
Алгоритм минимизации:
- Сортируем x по возрастанию. Это позволяет нам минимизировать произведение за счет выбора наименьших значений xi для умножения с наибольшими значениями yπ(i).
- Сортируем y по убыванию. Это обеспечит уменьшение суммы произведений, так как большие значения y будут умножаться на меньшие значения x.
- Считаем сумму произведений. Для каждого i берем x[i] из возрастающего списка и y[i] из убывающего списка и перемножаем.
Сортировка занимает O(n log n), вычисление суммы – O(n). Таким образом, общая сложность алгоритма составляет O(n log n), что делает его оптимальным для больших n.
Вариант 1:
def min_scalar_prod(x, y):
if len(x) != len(y):
raise ValueError("Длины векторов x и y должны совпадать")
x_sorted = sorted(x)
y_sorted = sorted(y, reverse=True)
return sum(x_sorted[i] * y_sorted[i] for i in range(len(x_sorted)))
x = [3, 5, 4, 2, 6, 7]
y = [4, 5, 3, 2, 6, 2]
print(min_scalar_prod(x, y))
Вариант 2 (с NumPy):
import numpy as np
def min_scalar_prod(x, y):
if len(x) != len(y):
raise ValueError("Длины векторов x и y должны совпадать")
x_sorted = np.sort(x)
y_sorted = np.sort(y)[::-1]
return np.dot(x_sorted, y_sorted)
x = [3, 5, 4, 2, 6, 7]
y = [4, 5, 3, 2, 6, 2]
print(min_scalar_prod(x, y))
Результат:
84
Назад в будущее
Ученый построил машину времени и может отправлять себя в прошлое. Однако ему стало интересно, сколько его копий могут оказаться в одном моменте времени, если он многократно возвращается в разные промежутки.
Ваша задача – определить максимальное количество копий ученого в одном моменте времени.
Формат входных данных:
- Первая строка содержит целое число N (1≤ N ≤106) – количество временных интервалов.
- Следующие N строк содержат два целых числа Di, Fi (0 ≤ Di ≤ Fi ≤ 109) – годы, в которые ученый появлялся и исчезал из прошлого (интервал правооткрытый: включает Di, но не включает Fi).
Формат выходных данных: Выведите единственное число – максимальное количество копий ученого, присутствующих одновременно в одном моменте времени.
Решение
Эта задача сводится к классической проблеме поиска максимального числа пересекающихся интервалов с использованием алгоритма заметающей прямой:
Создадим список событий:
- Прибытие в Di увеличивает счетчик на +1.
- Возвращение в Fi уменьшает счетчик на -1.
Отсортируем события:
- По времени (по возрастанию).
- Если два события имеют одинаковое время, возвращение -1 обрабатывается раньше прибытия +1 – это важно для корректного учета интервалов.
Просканируем события, считая активные пересечения, обновляя максимум.
Сложность алгоритма – O(N log N):
import sys
def max_self_occurrences(N, intervals):
events = []
# Формируем список событий: вход (D, +1) и выход (F+1, -1)
for d, f in intervals:
events.append((d, 1)) # Прибытие в момент D
events.append((f + 1, -1)) # Уход сразу после момента F
# Сортируем события: по времени, при одинаковом времени - сначала -1, затем +1
events.sort(key=lambda event: (event[0], event[1]))
max_copies = 0
current_copies = 0
for _, change in events:
current_copies += change
max_copies = max(max_copies, current_copies)
return max_copies
N = int(sys.stdin.readline().strip())
intervals = [tuple(map(int, sys.stdin.readline().split())) for _ in range(N)]
print(max_self_occurrences(N, intervals))
Результат:
3
Определение дня недели по дате

Напишите программу, с помощью которой можно определить, на какой день недели приходится введенная дата.
Пример ввода:
Введите дату в формате dd.mm.yyyy: 27.06.2025
Ожидаемый вывод:
пятница
Решение
Задача решается с помощью алгоритма конгруэнтности Целлера. Алгоритм позволяет определить, на какой день недели выпадет любая дата. Он учитывает коррекции для високосных лет и сдвиги календаря. Для григорианского календаря формула Целлера выглядит так:
где:
- h – число от 0 до 6, обозначающее день недели (0 = суббота, 1 = воскресенье, 2 = понедельник и т. д.)
- q – день месяца.
- m – номер месяца (март = 3, ..., декабрь = 12, январь = 13, февраль = 14 предыдущего года – nапример, для 5 января 2024 года нужно использовать m = 13, year = 2023).
- K – последние две цифры года (year mod 100).
- J – первые две цифры года (year // 100).
def zeller_congruence(day, month, year):
days = {
0: "воскресенье",
1: "понедельник",
2: "вторник",
3: "среда",
4: "четверг",
5: "пятница",
6: "суббота"
}
# Проверка диапазона месяца и дня
if not (1 <= month <= 12):
return "Неверный формат даты: месяц должен быть от 1 до 12"
if not (1 <= day <= 31):
return "Неверный формат даты: день должен быть от 1 до 31"
# Коррекция для января и февраля
if month < 3:
month += 12
year -= 1
c = year // 100
year = year % 100
h = (c // 4 - 2 * c + year + year // 4 + 13 * (month + 1) // 5 + day - 1) % 7
return days.get((h + 7) % 7)
def get_date_from_input():
date_str = input("Введите дату в формате dd.mm.yyyy: ")
try:
day, month, year = map(int, date_str.split('.'))
return day, month, year
except ValueError:
print("Ошибка ввода! Используйте формат dd.mm.yyyy.")
return None
date = get_date_from_input()
if date:
day, month, year = date
print(zeller_congruence(day, month, year))
Максимальное приближение

У вас есть n целых чисел x0, x1,…, xn−1 (где n ≤ 20) и число b. Нужно составить арифметическое выражение, которое максимально близко приближает значение b, используя:
- Каждое число из входных данных не более одного раза.
- Операции +, -, *, / в любом количестве.
Ограничения:
- Вычитание допустимо лишь в том случае, если результат будет положительным.
- Деление разрешено только в том случае, если результат будет целым числом.
Пример: для набора чисел [5, 3, 4, 1, 8, 6] и целевого значения 12 выражение должно выглядеть так:
((((4+(6*8))-1)/3)-5) = 12
Решение
Задача решается с помощью полного перебора и динамического программирования. Полный перебор необходим, так как нам нужно учесть все возможные комбинации чисел и операций. Но динамическое программирование помогает избежать повторных вычислений, храня уже найденные выражения.
Основная идея алгоритма
Алгоритм строит словарь E, в котором для каждого подмножества S исходных чисел (от 0 до n-1) хранятся все возможные значения, которые можно получить, используя каждое число из S не более одного раза, вместе с соответствующими выражениями.
Пример работы
Для входных данных x = (3, 4, 1, 8) и подмножества S = {0, 1} (числа 3 и 4) в словаре E[S] будут храниться пары «значение → выражение»:
- 1 → 4 – 3 (результат вычитания)
- 3 → 3 (просто число)
- 4 → 4 (просто число)
- 7 → 3 + 4 (результат сложения)
- 12 → 3 * 4 (результат умножения)
Процесс вычисления
Чтобы вычислить E[S] для любого множества S, алгоритм:
- Перебирает все возможные разбиения S на два непустых подмножества L и R.
- Для каждого значения vL из E[L] (полученного выражением eL) и каждого значения vR из E[R] (полученного выражением eR) формирует новые значения, которые сохраняются в E[S].
Например, значение vL + vR можно получить выражением eL + eR.
Сложность алгоритма
Сложность в худшем случае превышает экспоненциальную:
- Нужно учесть количество бинарных деревьев с не более чем n листьями.
- Затем умножить на количество возможностей назначить операции внутренним узлам деревьев.
Однако, с ограничениями на вычитание и деление, на практике для значений n в пределах 20 наблюдаемая сложность остается приемлемой:
def arithm_expr_target(x, target):
n = len(x)
expr = [{} for _ in range(1 << n)]
for i in range(n):
expr[1 << i] = {x[i]: str(x[i])}
all_ = (1 << n) - 1
for S in range(3, all_ + 1):
if expr[S] != {}:
continue
for L in range(1, S): # Разбиваем S на два подмножества L и R
if L & S == L: # L должно быть подмножеством S
R = S ^ L # Дополняем до множества S
for vL in expr[L]: # Объединяем выражения из L
for vR in expr[R]: # с выражениями из R
eL = expr[L][vL]
eR = expr[R][vR]
expr[S][vL] = eL
if vL > vR: # Вычитание только если результат положительный
expr[S][vL - vR] = f"({eL}-{eR})"
if L < R: # Исключаем дублирующиеся перестановки
expr[S][vL + vR] = f"({eL}+{eR})"
expr[S][vL * vR] = f"({eL}*{eR})"
if vR != 0 and vL % vR == 0: # Только целочисленное деление
expr[S][vL // vR] = f"({eL}/{eR})"
# Ищем выражение, наиболее близкое к target
for dist in range(target + 1):
for sign in [-1, +1]:
val = target + sign * dist
if val in expr[all_]:
return f"{expr[all_][val]} = {val}"
return "Решение не найдено"
x = [5, 3, 4, 1, 7, 8, 6]
target = 15
print(arithm_expr_target(x, target))
Результат:
((((((6-1)*7)-8)-4)-3)-5) = 15
Комментарии