
Почему БД снижает производительность приложения
Код выполняется в оперативной памяти, а база данных читает и записывает данные с диска или через сеть. Даже с SSD и оптимизированными движками задержки при доступе к диску и сети значительно больше, чем у операций в памяти.
Как понять, что снижение производительности связано именно с базой данных? Обратите внимание на следующие признаки:
- Запросы к API выполняются медленно, несмотря на минимальную логику приложения.
- База данных вызывает стабильно высокую нагрузку на CPU.
- Запросы становятся медленнее по мере роста объема данных.
- Приложение плохо справляется с большим числом пользователей.
Эти симптомы говорят о том, что пора заняться оптимизацией базы данных.
Диагностика проблемы

Прежде чем приступать к оптимизации, необходимо определить конкретный источник проблем. Это можно сделать с помощью профилирования запросов и изучения метрик производительности.
Профилирование запросов
Каждая крупная СУБД предоставляет инструменты для анализа медленных запросов:
- MySQL и PostgreSQL – используйте
EXPLAIN ANALYZE, чтобы проверить планы выполнения запросов. - MongoDB – используйте
.explain(), чтобы проанализировать выполнение запроса. - Логи медленных запросов – выявите запросы, которые выполняются дольше всего.
Наример, этот запрос покажет, как база данных обрабатывает выборку, и выявит возможные задержки:
EXPLAIN ANALYZE SELECT * FROM orders WHERE status = 'pending';
Изучение ключевых метрик производительности
Мониторьте следующие показатели базы данных:
- Время выполнения запросов – какие запросы работают медленно на постоянной основе?
- Задержка при чтении/записи – испытывает ли база нагрузку из-за большого количества операций?
- Проблемы с блокировками – блокируют ли запросы друг друга?
- Пул соединений – не создается ли слишком много соединений с базой?
Определив медленные запросы, можно приступать к их оптимизации.
Блокировка баз данных и взаимоблокировки
Когда несколько запросов или транзакций выполняются одновременно, базы данных используют механизмы блокировки для обеспечения целостности данных. Эти механизмы предотвращают ситуации, когда разные транзакции могут мешать друг другу и нарушать согласованность данных.
Неправильное управление транзакциями может привести к взаимным блокировкам (дедлокам), когда две или более транзакции ожидают бесконечно, пока другие освободят блокировку. Это сильно снижает производительность и может привести к зависанию системы.
Типы блокировок
Существует три основных типа блокировок.
1. Блокировки на уровне строк:
- Блокируют отдельные строки, обеспечивая более высокую параллельность операций.
- Идеально подходят для OLTP-приложений с обработкой транзакций в реальном времени.
2. Блокировки на уровне таблиц:
- Блокируют всю таблицу, предотвращая изменения во время выполнения транзакции.
- Могут вызывать замедление работы системы.
3. Разделяемые и эксклюзивные блокировки:
- Разделяемые блокировки допускают множественное чтение данных.
- Эксклюзивные блокировки блокируют весь доступ до завершения операции.
Лучшие практики для предотвращения взаимоблокировок
Эти меры помогают минимизировать конфликты и повысить производительность базы данных:
- Делайте транзакции короткими и эффективными (выполняйте
commitкак можно раньше). - Обращайтесь к таблицам в одинаковом порядке во всех транзакциях.
- Используйте индексирование для уменьшения количества ненужных блокировок.
- Отслеживайте взаимоблокировки с помощью команд
SHOW ENGINE INNODB STATUS;(для MySQL) иpg_stat_activity(для PostgreSQL).
Оптимизация запросов в базе данных

Оптимизация запросов – это быстрый способ улучшить производительность базы данных. Вот несколько советов, как это можно сделать.
Используйте индексы (но с умом!)
Индексы ускоряют поиск, предотвращая полное сканирование таблицы. Но использовать их надо обдуманно.
❌ Плохой пример (без индекса на email):
SELECT * FROM users WHERE email = '[email protected]';
✅ Правильный вариант (добавляем индекс):
CREATE INDEX idx_email ON users(email);
С индексом база данных сразу находит нужные данные, а не проверяет каждую строку.
❗Но важно помнить:
Слишком много индексов замедляют операции записи (INSERT, UPDATE, DELETE). Индексируйте только те столбцы, по которым часто ищете.
Избегайте SELECT *, выбирайте только нужные столбцы
Если запрашивать все колонки, а нужны лишь несколько, это тратит ресурсы.
❌ Неоптимальный запрос:
SELECT * FROM orders WHERE status = 'pending';
✅ Лучший вариант:
SELECT id, customer_id, total_price FROM orders WHERE status = 'pending';
Так запрос передает меньше данных и выполняется быстрее.
Используйте JOIN, избегайте вложенных запросов
Базы данных умеют оптимизировать соединения JOIN, а вложенные запросы, напротив, приводят к избыточным вычислениям.
❌ Плохой пример с вложенным запросом:
SELECT * FROM orders WHERE customer_id IN (SELECT id FROM customers WHERE city = 'Moscow');
✅ Более эффективный вариант (используем JOIN):
SELECT orders.order_id
FROM orders
JOIN customers ON orders.customer_id = customers.id
WHERE customers.city = 'Moscow';
Архитектурные оптимизации

Помимо оптимизации запросов, важно использовать архитектурные решения, которые могут значительно повысить производительность базы данных. Разберем несколько ключевых подходов.
Оптимизация схемы базы данных
Структура таблиц влияет на скорость запросов, масштабируемость и использование памяти. Плохая схема приводит к медленным запросам, высоким затратам на хранение и проблемам с масштабированием. Вот как можно оптимизировать дизайн схемы для лучшей производительности:
1. Найти компромисс между нормализацией и денормализацией
Нормализация (3НФ и выше) уменьшает избыточность данных путем разбиения таблиц на меньшие, связанные сущности.
- Плюсы: экономит пространство и избегает аномалий обновления.
- Минусы: может замедлять запросы, ориентированные на чтение, из-за избыточных JOIN-операций.
Денормализация объединяет часто используемые данные для уменьшения JOIN-операций, делая чтение быстрее за счет дополнительного хранения и потенциальных проблем с обновлением.
- Плюсы: отлично подходит для аналитики и рабочих нагрузок с преобладанием операций чтения.
- Минусы: может привести к несогласованности данных, если не управлять ими должным образом.
💡Общее правило:
- Нормализуйте, когда ожидаете частые операции записи.
- Денормализуйте, когда преобладают операции чтения.
2. Правильно выбрать типы данных
Правильный выбор типов данных значительно влияет на производительность базы данных, особенно при работе с большими объемами информации:
- Выбирайте BIGINT вместо UUID для первичных ключей, если не требуется уникальность в распределенных системах. Тип BIGINT обеспечивает лучшую производительность и занимает меньше места в хранилище.
- Используйте BOOLEAN для значений true/false. Это наиболее эффективный способ хранения бинарных данных.
- Применяйте типы TEXT и JSONB осторожно. Поиск по индексируемым колонкам (VARCHAR, INTEGER, TIMESTAMP) выполняется намного быстрее.
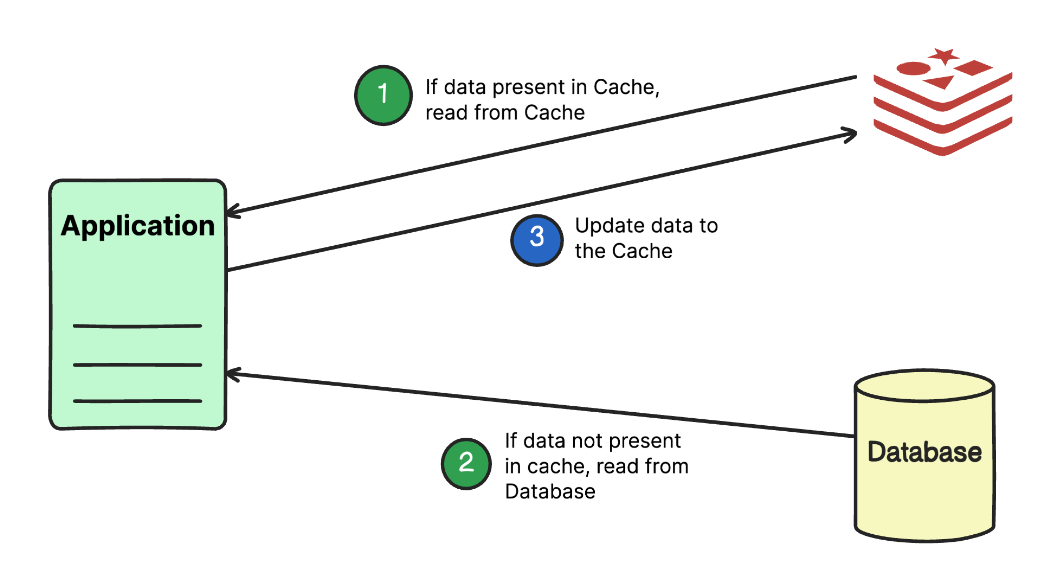
Кэширование
Вместо обращения к базе при каждом запросе храните часто используемые данные в кэше (например, Redis, Memcached). Это уменьшает нагрузку на базу данных и ускоряет обработку запросов.
❌ Пример: без кэширования каждый раз обращаемся к базе:
query_result = db.execute("SELECT * FROM orders WHERE user_id = 123")
✅ С кэшированием (данные хранятся в Redis, обновляются раз в 5 минут):
query_result = cache.get("user_123_orders")
if not query_result:
query_result = db.execute("SELECT * FROM orders WHERE user_id = 123")
cache.set("user_123_orders", query_result, expire=300) # Данные хранятся 5 минут
Где применять кэширование:
- Часто запрашиваемые данные (SELECT-запросы, популярные страницы).
- Данные, которые редко меняются (списки товаров, категории).
- Результаты сложных аналитических запросов.
Оптимизация соединений с базой данных
Открытие и закрытие соединений с базой относится к ресурсоемким операцием. Если при каждом запросе создавать новое соединение, это приведет к замедлению работы и высокой нагрузке на сервер. Лучшее решение – использование пула соединений (например, pgbouncer для PostgreSQL), который повторно использует уже открытые соединения вместо создания новых.
Материализованные представления
Материализованное представление – это результат SQL-запроса, сохраненный в виде отдельной физической таблицы. В отличие от обычных представлений, которые пересчитывают запросы при каждом обращении, материализованные позволяют быстро получать результаты без повторных вычислений.
МП стоит использовать, если:
- Запрос очень тяжелый и выполняется часто (например, отчеты, аналитика).
- Данные не требуют мгновенного обновления (например, суточные отчеты по продажам).
- Стандартные индексы не помогают ускорить выполнение сложных агрегатных запросов.
Пример: ускорение отчета по продажам
Допустим, мы часто вычисляем дневные продажи из огромной таблицы orders.
❌ Обычный SQL-запрос (медленный, если данных много):
SELECT order_date, SUM(total_price) AS daily_sales
FROM orders
GROUP BY order_date;
✅ Решение – создать материализованное представление:
CREATE MATERIALIZED VIEW daily_sales AS
SELECT order_date, SUM(total_price) AS total_sales
FROM orders
GROUP BY order_date;
Теперь вместо сложного запроса можно просто:
SELECT * FROM daily_sales;
Недостатки материализованных представлений:
- Не обновляются автоматически – если в orders появятся новые записи, материализованное представление не обновится само по себе. Нужно предусмотреть автоматический механизм обновления.
- Не подходят для работы с данными, которые обновляются в реальном времени.
- Занимают дополнительное место в базе, так как это физические таблицы.
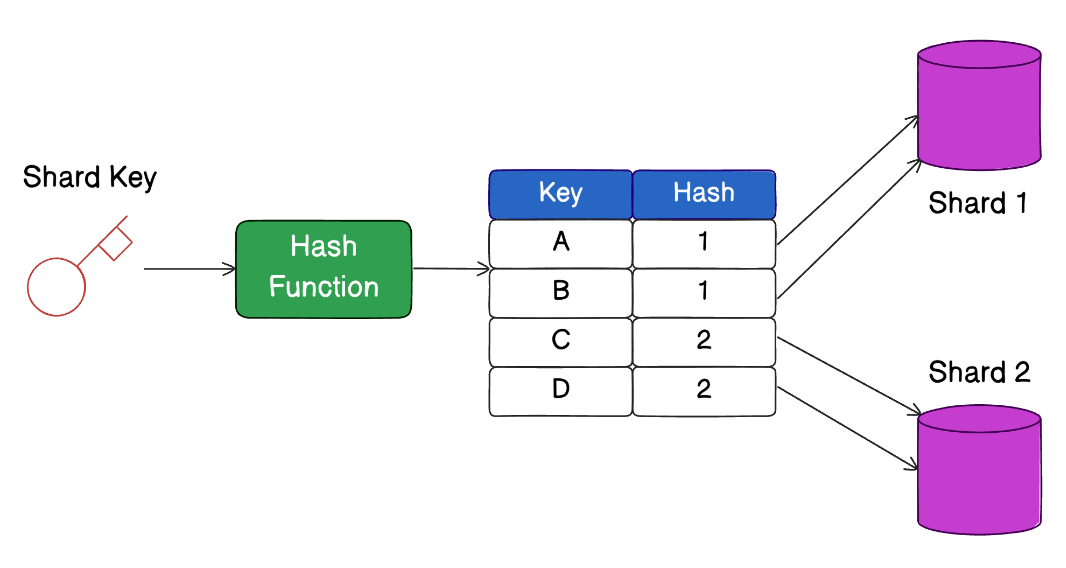
Шардирование и секционирование
Когда база данных становится очень большой, обычные запросы начинают замедляться, а нагрузка на сервер растет. Решение – разбить данные на части с помощью шардирования или секционирования:
- Шардинг – разделение данных по разным серверам. Пример – шардирование пользователей по регионам: users_us (пользователи из США), users_eu (из Европы), users_asia (из Азии). Запросы выполняются быстрее, поскольку каждый сервер обрабатывает только часть пользователей, а не всех сразу. Кроме того, можно горизонтально масштабировать базу (добавлять новые серверы) при росте нагрузки.
- Секционирование (партиционирование) – разделение данных внутри одной базы на логические части. Пример – разбиваем заказы по годам: orders_2023, orders_2024, orders_2025. Запросы работают быстрее, так как читают только нужные партиции, а не всю таблицу. Старые данные при этом можно хранить отдельно (в архиве).
Реплики базы данных
Если приложение выполняет миллионы операций чтения в секунду, создайте реплики базы данных, чтобы распределить нагрузку.
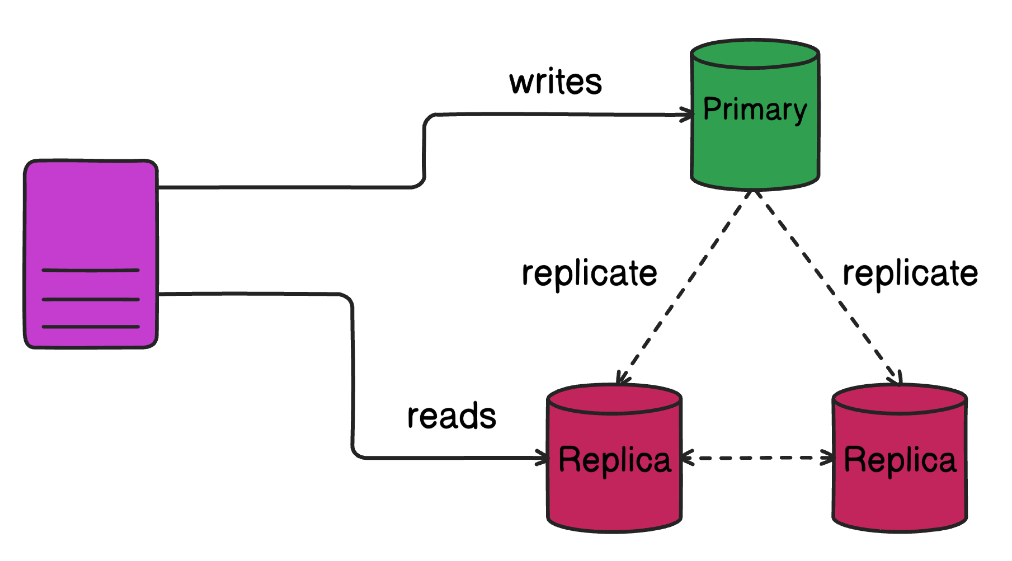
Как работает репликация:
- Основная база данных обрабатывает операции записи (INSERT, UPDATE, DELETE) и критически важные запросы на чтение.
- Реплики для чтения (копии основной базы данных) обрабатывают только обычные запросы на чтение (SELECT).
Этот подход широко используется в крупных системах для:
- Масштабирования – уменьшает нагрузку на основную базу.
- Отказоустойчивости – если основная база выйдет из строя, данные останутся доступными на репликах.
- Повышенной надежности – даже в случае сбоя можно быстро переключить трафик на реплику.
Реплики должны периодически синхронизироваться с основной базой, чтобы данные оставались актуальными.
Подведем итоги
База данных не должна становиться слабым звеном вашей системы. С правильными методами оптимизации систему можно сделать быстрой и масштабируемой. Важно:
- Не оптимизировать вслепую – используйте логи и профилирование, чтобы определить, что действительно замедляет систему.
- Начать с оптимизации запросов – индексы, корректное использование JOIN и пакетная обработка решают 80% проблем с производительностью.
- Использовать кэширование и реплики для чтения – это поможет снизить нагрузку на базу данных, исключив повторяющиеся запросы.
- Продумать масштабируемую архитектуру – шардирование, партиционирование и гибридные базы данных значительно повышают производительность приложения.
Следуя этим рекомендациям, вы сможете устранить узкие места и добиться высокой скорости работы приложения, даже при росте нагрузки.
Комментарии