

Даже если вам еще не приходилось напрямую сталкиваться с Kubernetes, скорее всего, вы знаете, что это особая платформа для управления виртуальными контейнерами, в которых находятся приложения со всеми необходимыми зависимостями. А ваш опыт работы с контейнерами, очевидно, зависит от того, насколько серьезно в вашей компании относятся к DevOps: вполне возможно, что вы просто пишите код, не заботясь о том, кто и как разворачивает и масштабирует готовые приложения в продакшене. Чтобы разобраться в том, как это происходит, нужно начать с основ: что вообще входит в понятие запуск приложения.
Что нужно для запуска приложения
Это во многом зависит от языка и его экосистемы. Если вы, к примеру, пишите на Java, то все свои исходники вы собираете в один исполняемый .jar файл, который запускается с помощью простой команды:
java -jar myNewAIStartup.jar
Для работы приложения обычно требуются какие-то настройки – учетная запись для доступа к базе данных, API-ключи, секреты и т. д. При использовании, скажем, Spring Boot все эти настройки можно хранить в файле application.properties. Не возбраняется воспользоваться каким-то сторонним сервисом для управления этими данными. Но в любом случае, команда для запуска приложения будет одной и той же, независимо от того, где вы это приложение запускаете – на реальном сервере, в виртуальной машине, в Docker-контейнере (с Kubernetes или без), или на тостере с поддержкой Java.
Если все так просто, в чем же подвох?
На любом айтишном форуме есть масса обсуждений проблем, которые неизбежно возникают при развертывании приложения:
- Что делать, если возник конфликт между версиями ОС (библиотек, модулей, инфраструктуры и т. д.) в среде разработки и в продакшене?
- Как решить проблему с отсутствующими пакетами ОС?
- Что, если вместо деплоя на каком-то конкретном облачном сервисе нужно развернуть приложение на другой платформе с радикально отличающейся конфигурацией?
Сложность решения этих проблем сильно зависит от языка: в случае с приложением на Java достаточно установить JDK, и все заработает. Но если приложение написано на PHP, Python или Node – страдать и возиться придется намного больше. Поэтому и были придуманы контейнеры.
Что такое Docker, Docker Compose и Swarm

Как работают контейнеры Docker
Docker, в двух словах, – это инструмент для упаковки вашего код в контейнер, который можно легко развернуть на любой машине, где установлен Docker. Как это работает?
- Вы компилируете исходный код в исполняемый файл, например, Java-код – в .jar файл. А если код, скажем, на Python, то и компилировать ничего не надо.
- Затем вы создаете новый Docker-образ, который включает в себя этот .jar файл. Образ также содержит все дополнительное программное обеспечение и настройки, необходимые для успешного запуска.
- Вместо запуска вашего jar-файла, вы теперь развертываете Docker-образ и запускаете Docker-контейнер.
Прелесть этого подхода состоит в том, что на целевом сервере можно запустить любой Docker-образ (при условии, что на этом сервере установлен Docker, и ОС совместима с Docker-контейнером):
docker run --name my-new-ai-startup -p 80:8080 -d mynewaistartup
// yay, your application is deployed
// This will start a Docker container based on the `_mynewaistartup_` Docker image.
// That image will, that other things, contain your e.g. -jar file,
// a web application which runs on port 8080, as well as instructions on how to run it.
// Hint: These instructions are `_java -jar mynewaistartup.jar_`.
В чем заключается «развертывание» Docker-образов?
После того, как приложение упаковано в Docker-образ (собственноручно или CI/CD-сервером), этот образ отправляется в любой из множества Docker-реестров – Docker Hub, Amazon ECR, GitLab и т. д. Как только образ оказался в реестре, вы можете войти в этот реестр на своем целевом сервере:
docker login mysupersecret.registry.com
И запустить нужный образ с помощью команды docker run:
docker run --name my-new-ai-startup -p 80:8080 -d mynewaistartup
//....
SUCCESS!
Docker Compose – одновременный запуск нескольких контейнеров
Если ваше приложение состоит из 100500 микросервисов и занимает несколько контейнеров – на помощь придет Docker Compose. Все сервисы и зависимости между ними (какой запускать первым и т. п.) определяются в старом добром YAML-файле, compose.yaml. Вот пример такого файла – здесь определены два сервиса, веб-сервер и Redis:
services:
web:
build: .
ports:
- "8000:5000"
volumes:
- .:/code
- logvolume01:/var/log
depends_on:
- redis
redis:
image: redis
volumes:
logvolume01: {}
Остается выполнить команду docker compose up, и вся среда (состоящая из всех сервисов, работающих в отдельных Docker-контейнерах) будет запущена. При таком подходе все ваши контейнеры будут работать на одном и том же сервере. Если нужно масштабировать эту задачу на несколько машин, потребуется Docker Swarm.
Хотя Docker Compose чаще всего используют для быстрого запуска среды разработки или тестирования, он также хорошо подходит для продакшена на одном хосте. Если:
- Приложение обслуживает умеренное количество пользователей и не нуждается в масштабировании для обеспечения максимальной доступности при высокой нагрузке.
- Вы не против кое-какой ручной работы (SSH вход в систему,
docker compose up/down) или готовы использовать дополнительный инструмент типа Ansible. - У компании нет желания делать серьезные инвестиции в DevOps-команду.
...то использование Docker Compose для продакшена может стать оптимальным решением.
Основные концепции Kubernetes
Kubernetes оптимально подходит для разворачивания приложения, если:
- Нужно автоматически запускать сотни и тысячи контейнеров.
- Не хочется вникать в аппаратную конфигурацию и другие нюнсы многочисленных и разнообразных серверов, на которых будут работать контейнеры.
- Хочется максимально оптимизировать использование ресурсов в зависимости от нагрузки на приложение.
Основные термины
Ваше приложение (или рабочая нагрузка в терминологии Kubernetes) должно где-то работать, будь то виртуальный или физический сервер. Этот сервер называется узлом (или нодой) в кластере Kubernetes. Кластер имеет как минимум один рабочий узел (ноду).
Kubernetes планирует, развертывает и запускает поды. Под содержит от одного до нескольких контейнеров, причем помимо обычных Docker-контейнеров поддерживаются и другие – например, containerd и CRI-O.
Для управления нодами в кластере используется Control Plane, состоящий из нескольких компонентов:
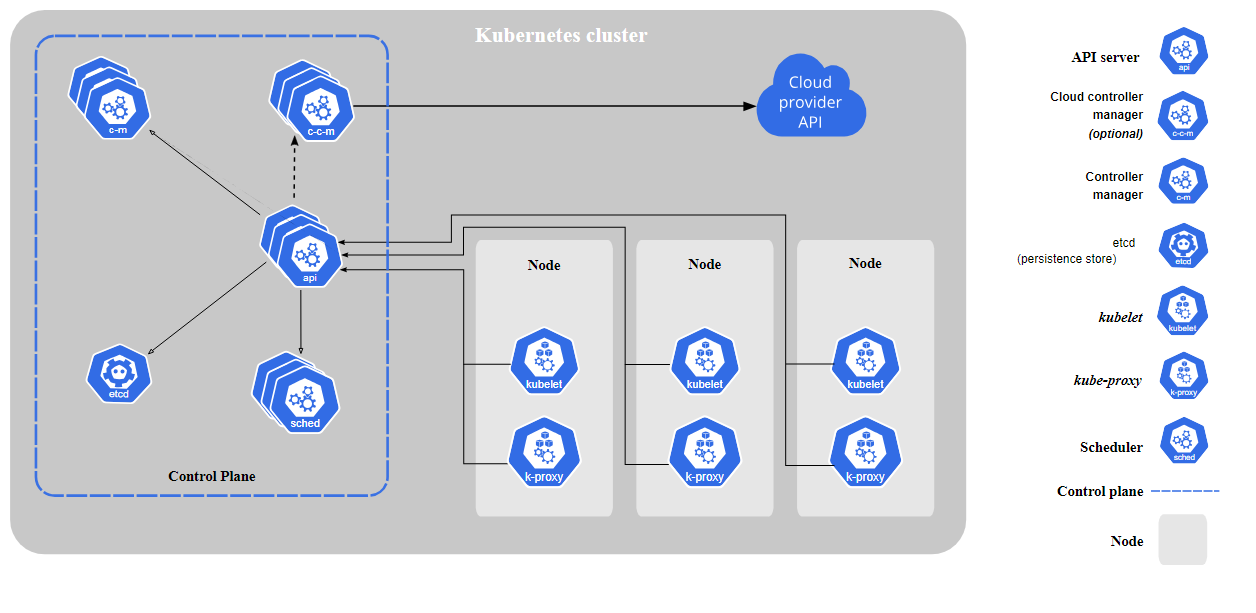
Среди прочего, Control Plane:
- Позволяет планировать запуск приложений – то есть размещать поды на нодах.
- Проверяет состояние подов и перезапускает их при необходимости.
- Масштабирует приложение (запускает дополнительные поды) при увеличении нагрузки.
Мониторингом состояния кластера занимается Scheduler (планировщик). Планировщик непрерывно собирает данные о доступных узлах и их ресурсах. Как только в кластере появляется новый под, нуждающийся в размещении, планировщик подбирает для него оптимальный узел, исходя из требований пода к процессору, объему памяти и т. д.
Помимо основых компонентов, в Kubernetes есть дополнительные. Самый большой интерес для разработчиков представляет веб-интерфейс для управления кластером. Крупные облачные провайдеры, однако, обычно предоставляют собственные дашборды.
Основы работы с Kubernetes
Чтобы приступить к работе с платформой, нужны:
- Доступ к Kubernetes в облаке или локальная установка Minikube.
- Файл kubeconfig. По умолчанию находится в ~/.kube/config. Minikube создает этот файл автоматически, а облачные провайдеры рассказывают о способах его получения в документации.
- CLI-инструмент для управления кластером kubectl (кьюб контрол).
Файл kubeconfig содержит данные о кластерах, пользователях и контексте в YAML-формате. Контекст — это сопоставление, которое включает в себя описания кластера и пользователя, а также название, с помощью которого можно ссылаться на конфигурацию для аутентификации кластера и взаимодействия с ним:
apiVersion: v1
clusters:
- cluster:
certificate-authority: fake-ca-file
server: https://1.2.3.4
name: development
- cluster:
insecure-skip-tls-verify: true
server: https://5.6.7.8
name: test
contexts:
- context:
cluster: development
namespace: frontend
user: developer
name: dev-frontend
- context:
cluster: development
namespace: storage
user: developer
name: dev-storage
- context:
cluster: test
namespace: default
user: experimenter
name: exp-test
current-context: ""
kind: Config
preferences: {}
users:
- name: developer
user:
client-certificate: fake-cert-file
client-key: fake-key-file
- name: experimenter
user:
# Documentation note (this comment is NOT part of the command output).
# Storing passwords in Kubernetes client config is risky.
# A better alternative would be to use a credential plugin
# and store the credentials separately.
# See https://kubernetes.io/docs/reference/access-authn-authz/authentication/#client-go-credential-plugins
password: some-password
username: exp
В самом упрощенном виде, управление кластером состоит в том, чтобы запланировать и осуществить запуск n-го числа подов на узле (узлах). Это делается с помощью манифестов — YAML-файлов с описаниями нужного состояния кластера. Манифесты загружаются в kubectl, который и приводит кластер в необходимое состояние.
Пример манифеста
Манифест имеет расширение .yaml (например, marcocodes-pod.yaml) и выглядит примерно так:
apiVersion: v1
kind: Pod
metadata:
name: marcocodes-web
spec:
containers:
- image: gcr.io/marco/marcocodes:1.4
name: marcocodes-web
ports:
- containerPort: 8080
name: http
protocol: TCP
Этот файл нужно передать в kubectl с помощью команды:
kubectl apply -f marcocodes-pod.yaml
Что именно определено в этом манифесте? Разберем шаг за шагом:
kind: Pod
Kubernetes распознает несколько типов объектов, поды — один из них. Здесь мы указываем, что тип объекта — Pod.
metadata:
name: marcocodes-web
В метаданных описываются свойства объекта, в этом случае мы указываем уникальное название, по которому Kubernetes будет идентифицировать под.
spec:
containers:
- image: gcr.io/marco/marcocodes:1.4
name: marcocodes-web
ports:
- containerPort: 8080
name: http
protocol: TCP
Здесь мы указываем конкретный Docker-образ и открываем для него порт 8080 через HTTP. Поды могут содержать несколько контейнеров, тогда в YAML указываются параметры каждого из них.
Как выполняется манифест
Когда вы запускаете команду kubectl apply, ваш файл YAML отправляется на API-сервер. Затем Kubernetes находит подходящий узел в кластере, на котором будет запущен контейнер marcocodes 1.4. Kubernetes использует цикл согласования (reconcilliation loop), чтобы отслеживать текущее состояние кластера и сравнивать его с тем, что указано в файле YAML. Если пользователь хочет создать новый контейнер или добавить хранилище, Kubernetes автоматически выполняет эти действия.
Ресурсы и разделы
В манифесте можно (и нужно!) определить ресурсы, которые необходимы вашему контейнеру для нормальной работы:
# ....
spec:
containers:
- image: gcr.io/marco/marcocodes:1.4
resources:
requests:
cpu: "500m"
memory: "128Mi"
# ....
Это обеспечит контейнеру минимум 0.5 CPU и 128 Мб памяти. Здесь же с помощью limits можно задать верхний лимит использования ресурсов:
limits:
cpu: "1"
Когда контейнер в поде удаляется или перезапускается, данные в файловой системе контейнера также удаляются. Чтобы избежать этого, можно хранить данные в постоянном разделе:
# ....
spec:
volumes:
- name: "marcocodes-data"
hostPath:
path: "/var/lib/marcocodes"
containers:
- image: gcr.io/marco/marcocodes:1.4
name: marcocodes
volumeMounts:
- mountPath: "/data"
name: "marcocodes-data"
ports:
- containerPort: 8080
name: http
protocol: TCP
# ....
Здесь мы создали один раздел, который будет называться marcocodes-data. Этот том будет монтироваться в директории /data внутри контейнера и будет находиться в /var/lib/marcocodes на хостовой машине.
В чем же преимущество по сравнению с docker run?
Итак, в Kubernetes используются поды, которые состоят из одного или нескольких Docker-контейнеров, а правилa потребления ресурсов и хранение данных для них можно настроить в манифесте.
Используя один такой YAML-манифест, мы смогли запланировать запуск одного статического одноразового пода. Зададимся вопросом: в чем преимущество этого подхода перед простым запуском команды docker run -d --publish 8080:8080 gcr.io/marco/marcocodes:1.4?
Верно, на данный момент никаких преимуществ нет. Чтобы их получить, нужно вникнуть в концепции ReplicaSets и Deployments.
ReplicaSets
Популярное приложение, которое испытывает постоянную и серьезную нагрузку от множества пользователей, нуждается в автоматическом масштабировании. Такое приложение нужно запускать в нескольких экземплярах, — для равномерного распределения нагрузки между ними. Один из способов решения этой задачи —репликация с помощью ReplicaSets:
apiVersion: apps/v1
kind: ReplicaSet
# metadata:
# ...
spec:
replicas: 2
selector: "you will learn this later"
# ...
template:
metadata: "you will learn this later"
# ...
spec:
containers:
- name: marcocodes-web
image: "gcr.io/marco/marcocodes:3.85"
Тип объекта в этом файле теперь не Pod, а ReplicaSet:
kind: ReplicaSet
Так мы определяем количество экземпляров (подов), которые должны работать постоянно:
spec:
replicas: 2
После выполнения команды kubectl apply -f marcocodes-rs.yaml Kubernetes получит список подов с API-сервера, отфильтрует результаты по метаданным, и в зависимости от числа необходимых реплик, создаст или удалит нужное количество экземпляров приложения.
Однако при создании экземпляров с помощью ReplicaSets возникают две проблемы:
- Реплики привязаны к конкретной версии контейнера (в нашем случае это 3.85) и эти версии не должны меняться.
- ReplicaSets не помогают избежать простоя в процессе развертывания новых версий приложения.
Поэтому нам нужна дополнительная концепция, которая поможет управлять выпуском новых версий. Такая концепция в Kubernetes есть — она называется Deployments (деплойменты, развертывания).
Deployments
Deployments используются для управления экземплярами, созданными с помощью ReplicaSets:
apiVersion: apps/v1
kind: Deployment
metadata: "ignore for now"
# ...
spec:
progressDeadlineSeconds: 600
replicas: 2
revisionHistoryLimit: 10
selector: "ignore for now"
# ...
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
"ignore for now"
# ...
Это, конечно, очень упрощенный и минималистичный пример. Для развертывания в Kubernetes используются еще примерно 100500 дополнительных пар ключ-значение. На этом этапе достаточно знать, что в Kubernetes есть две основные стратегии обновления программного обеспечения — rollingUpdate и recreate:
- recreate убивает все старые версии ваших контейнеров и создает новые, что может привести к временной недоступности для пользователей.
- rollingUpdate позволяет обновлять программное обеспечение, продолжая обслуживать трафик через старые контейнеры, что обычно предпочтительнее.
Kubernetes — не волшебная пилюля
Подобие метода rollingUpdate существовало задолго до появления Kubernetes — тогда обновления делали с помощью bash-скриптов через ssh. И проблема, которая существовала в то время, не решается Kubernetes автоматически и сейчас: в течение короткого промежутка времени, пока кластер должен поддерживать и старую, и новую версии ПО, работоспособность приложения может быть нарушена, особенно если в новой версии есть значительные изменения в структуре базы данных и/или API.
Если же обновление пройдет неудачно, функция self-healing (самолечение), которая есть в Kubernetes, может решить проблему лишь частично: она отключит зависший под или запустит вместо него новый, но исправить ошибочную миграцию в базе данных, которая способна парализовать весь кластер, self-healing не сможет.
Как автоматизировать управление кластером
До сих пор все примеры, которые мы рассмотрели, требовали какой-то ручной работы. Для управления кластером применяются файлы YAML, и даже при использовании Deployments, в случае появления новой версии контейнера, нужно вручную отредактировать файл, сохранить его и применить. Если эту работу надо автоматизировать, придется использовать дополнительные инструменты, — например, Helm или Kustomize.
Что такое Helm и Helm Charts

Установка любого приложения, скажем Wordpress, в кластер Kubernetes влечет за собой необходимость написать тысячи строк в YAML-файлах. И было бы здорово, если бы не пришлось писать эти строки самостоятельно, а использовать какой-то предварительно собранный типовой пакет, в котором пришлось бы заменить всего несколько переменных.
Такую возможность предоставляют Helm чарты (Helm Charts). Чарт — это набор файлов YAML и шаблонов, расположенных в определенной иерархической структуре. Когда вы устанавливаете конкретный чарт, Helm загружает его, анализирует шаблоны и, используя ваши значения, генерирует все нужные манифесты, которые затем отправляет в ваш Kubernetes. Вот так может выглядеть небольшой фрагмент одного из таких шаблонных файлов (для манифеста развертывания):
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ include "myChart.name" . }}
labels:
{{- include "myChart.labels" . | nindent 4 }}
Популярные чарты можно взять на https://artifacthub.io/.
Установка приложения с помощью Helm Chart
Helm можно рассматривать как менеджер пакетов для Kubernetes: он помогает определить конфигурацию, установить и обновить даже самое сложное приложение. Вот так будет выглядеть установка Wordpress в кластер Kubernetes при использовании Helm и готового чарта:
1. Устанавливаем Helm Client.
2. Устанавливаем нужный чарт для Wordpress, одновременно загружая в него наши собственные данные в values.yaml или указывая их вручную:
helm install my-release oci://registry-1.docker.io/bitnamicharts/wordpress --values values.yaml
// или вручную
helm install my-release oci://registry-1.docker.io/bitnamicharts/wordpress --set wordpressUsername=m4rc0 // и так далее...
Что такое Kustomize
Как уже упоминалось выше, Helm использует шаблоны для генерации манифестов Kubernetes. Это означает, что кто-то должен выполнить непростую работу по созданию шаблонов Helm из манифестов Kubernetes, а затем поддерживать их в актуальном состоянии, чтобы конечные пользователи могли использовать готовые чарты для быстрой установки приложений в командной строке Helm.
Разработчики Kustomize пошли другим путем: вместо использования шаблонов с плейсхолдерами, этот инструмент позволяет создавать пользовательские версии манифестов, накладывая ваши дополнительные изменения (оверлеи, «перекрытия») поверх исходного файла. В ходе этого процесса вы получите файловую структуру, например, такую:
├── deployment.yaml // исходный манифест
└── kustomization.yaml // кастомизация (может состоять из нескольких поддиректорий для различных сред - development/staging/prod)
После подготовки всех нужных перекрытий выполняют команду kustomize build для создания финального варианта .yaml, который отправляют на исполнение в kubectl:
kustomize build . | kubectl apply -f -
Kustomize и Helm можно использовать вместе или по отдельности в зависимости от нужд команды разработки. В большинстве случаев, выбор между Helm и Kustomize зависит от конкретных требований, сложности проекта, предпочтений в работе с конфигурациями и привычек команды.
Подведем итоги: когда следует использовать Kubernetes?
В целом, чем сложнее инфраструктура и архитектура, тем больше преимуществ дает Kubernetes:
- Eсть потребность в управлении сотнями и тысячами контейнеров? Kubernetes отлично масштабируется на большие кластеры и позволяет эффективно распределять нагрузку.
- Требуется высокая отказоустойчивость приложений? Kubernetes автоматически реплицирует поды при сбоях, перезапускает упавшие контейнеры и балансирует нагрузку.
- Нужно быстро разворачивать и масштабировать? В Kubernetes можно легко определять инфраструктуру как код и запускать новые приложения буквально одной командой.
- Нужен простой и унифицированный способ развертывания как в локальной инфраструктуре, так и в публичных облаках? Kubernetes хорошо абстрагирует инфраструктурный уровень.
- Требуется сложная координация и взаимодействие между сервисами? Kubernetes предоставляет сервисную сеть для открытия и балансировки подов.
Но в случаях попроще лучше обойтись без Kubernetes: это достаточно сложная платформа, разобраться в которой на должном уровне могут лишь опытные специалисты. Нанимать таких специалистов — дорого, а ждать, пока собственная команда вникнет во все тонкости — долго. Поэтому внедрение Kubernetes имеет смысл только в том случае, когда его преимущества в масштабировании и отказоустойчивости критичны для продукта — в противном случае сложность может перевесить выгоды.
При подготовке статьи использовалась публикация "Kubernetes for lazy developers".



Комментарии