

Регулярные выражения (Regex) – это особые шаблоны для поиска определенных подстрок в текстовых документах и на веб-страницах. Концепция Regex появилась в 1951 году, стала популярной к 1968 году, и с тех пор в той или иной степени поддерживается в большинстве языков программирования общего назначения. Регулярные выражения используются в текстовых редакторах, в файловых менеджерах ОС, в OCR-приложениях для распознавания текста, в онлайн-поисковиках и браузерах. Кроме того, они применяются для:
- валидации данных;
- лексического анализа;
- определения директив конфигурации и преобразования URL (Apache http.conf, mod_rewrite);
- составления сложных SQL-запросов;
- создания кастомных шаблонов URL-диспетчера (re_path() Django).
Регулярные выражения в Python
Для работы с Regex в Python используют встроенный модуль re, в который входят:
- Набор функций для поиска и замены подстрок – ниже мы подробно рассмотрим примеры использования основных методов.
- Компилятор re.compile – он создает Regex-объекты для повторного использования и ускоряет работу регулярных выражений, как мы увидим чуть позже.
Регулярные выражения состоят из литералов (букв и цифр) и метасимволов. Для экранирования спецсимволов применяют обратные слэши \, или же заключают выражение в r-строку . Такой шаблон, к примеру, можно использовать для валидации email-адреса:
r'^[a-zA-Z0-9._-]+@[a-zA-Z-.]+$'
Этот шаблон – один из простейших, Regex-выражения для проверки email-адресов могут выглядеть гораздо сложнее. Для разработки и тестирования сложных Regex шаблонов используют специальные сервисы, например, Regex101:
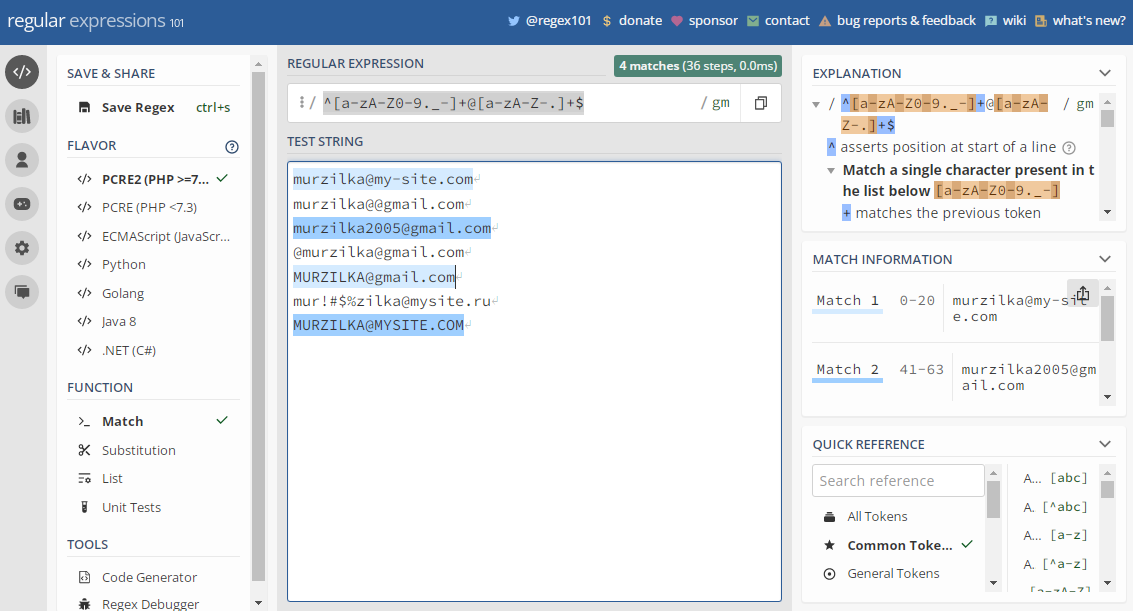
Основные Regex методы в Python
re.match() – проверяет, начинается ли строка с нужного фрагмента:
import re
lst = ['abrakadabra', 'https://kadabra.com', 'https://proglib.io/p/weekly-23-novosti-podkasty-otbornye-stati-i-obuchayushchie-materialy-po-frontendu-2023-02-14 - статья по этой ссылке',
'http//:mysite.ru', 'www.abra.com', 'http//abra.com', 'https://abra.com/', 'это мой сайт - https://abrakadabra.com/',
'https://ru.wikipedia.org/wiki/%D0%9B%D1%8F%D0%B3%D1%83%D1%88%D0%BA%D0%B0-%D0%B3%D0%BE%D0%BB%D0%B8%D0%B0%D1%84']
url = r'https?://(www.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b([-a-zA-Z0-9()!@:%_+.~#?&/=]*)'
for i in lst:
m = re.match(url, i)
if m:
print(m.group(0)) # валидная ссылка извлекается из начала строки
Вывод:
https://kadabra.com
https://proglib.io/p/weekly-23-novosti-podkasty-otbornye-stati-i-obuchayushchie-materialy-po-frontendu-2023-02-14
https://abra.com/
https://ru.wikipedia.org/wiki/%D0%9B%D1%8F%D0%B3%D1%83%D1%88%D0%BA%D0%B0-%D0%B3%D0%BE%D0%BB%D0%B8%D0%B0%D1%84
Если нужный фрагмент содержится в тексте, но не в начале строки – re.match() вернет None:
>>> import re
>>> s = 'ой, мороз, мороз, не морозь меня'
>>> print(re.match('мороз', s))
None
Метод re.fullmatch() возвращает совпадение, если вся строка полностью соответствует шаблону:
>>> st1, st2 = 'одна строка', 'строка'
>>> print(re.fullmatch(r'строка', st1))
None
>>> print(re.fullmatch(r'строка', st2))
<re.Match object; span=(0, 6), match='строка'>
Чтобы найти первое вхождение подстроки в текст, используют re.search(), при необходимости – с флагом re.I для игнорирования регистра:
>>> s = 'Синий, синий иней лег на провода'
>>> print(re.search('синий', s, re.I))
<re.Match object; span=(0, 5), match='Синий'>
Метод re.search() можно использовать с
дополнительными параметрами span(),
string
и group().
span возвращает начальный и конечный индексы вхождения:
>>> text = 'Однажды весною, в час небывало жаркого заката, в Москве, на Патриарших прудах, появились два гражданина.'
>>> print(re.search('пруд', text).span())
(71, 75)
string возвращает строку, содержащую искомый фрагмент:
>>> st = 'Дракула Брэма Стокера'
>>> print(re.search('Сток', st).string)
Дракула Брэма Стокера
group вернет подстроку, совпадающую с запросом:
>>> st = 'пример домашнего хищника: кот'
>>> print(' текст найден - ', re.search(r'хищника:\s\w\w\w', st).group())
текст найден - хищника: кот
Все вхождения фрагмента можно найти с помощью re.findall():
>>> st = 'Eins Hier kommt die Sonne, Zwei Hier kommt die Sonne'
>>> print(re.findall('Hier kommt die Sonne', st))
['Hier kommt die Sonne', 'Hier kommt die Sonne']
Метод re.split() разделяет строку по заданному шаблону:
>>> st = 'мороз и солнце, день чудесный'
>>> print(re.split(r'\sи\s', st, 1))
['мороз', 'солнце, день чудесный']
Для замены символов и подстрок используют re.sub(). В этом примере регулярное выражение предусматривает удаление из текста всех символов, кроме букв, цифр, знака перевода на новую строку, точки, пробела, вопросительного знака и запятой:
>>> st = 'П#$%^рив&*ет, ка@!к успе~@хи с Py$%^*&thon?'
>>> print(re.sub('[^а-яА-Яa-zA-Z0-9,? \n\.]', '', st))
Привет, как успехи с Python?
Скорость работы скомпилированных Regex-выражений
Компилятор re.compile() применяют в тех случаях, когда шаблон выражения используется повторно:
import re
url_lst = ['https://mysite.ru/uploads/2023/2/1/image.jpg',
'https://mysite.ru/uploads/2023/2/1/image.html',
'http://www.mysite.ru/uploads/2022/2/1/another_image.png',
'http://mysite.ru/uploads/2022/12/15/images.doc',
'https://www.mysite.ru/uploads/2022/12/11/image22.jpg',
'http://mysite.ru/images/2023/2/5/gifimage.gif',
'https://mysite.ru/texts/2023/2/1/novel.txt',
'https://mysite.ru/books/2023/2/1/book.epub']
img_url = re.compile(r'https?://(www)?.*.(png|jpg|gif)')
for url in url_lst:
if img_url.match(url):
print(url)
Вывод:
https://mysite.ru/uploads/2023/2/1/image.jpg
http://www.mysite.ru/uploads/2022/2/1/another_image.png
https://www.mysite.ru/uploads/2022/12/11/image22.jpg
http://mysite.ru/images/2023/2/5/gifimage.gif
Как уже упоминалось выше, скомпилированные выражения удобны не только потому, что их можно использовать многократно – они, к тому же, быстрее работают. Чем сложнее выражение и чем больше объем обрабатываемых данных – тем очевиднее преимущество. Проверим, насколько отличается скорость работы обычного регулярного выражения от скомпилированного – возьмем объемный файл («Преступление и наказание» Ф. М. Достоевского) и проведем поиск всех строк, в которых одновременно содержатся имя «Родион» и фамилия «Раскольников» в любых возможных склонениях, при этом между именем и фамилией должно быть не более 5 других слов:
import re
import time
start = time.time()
with open('prestuplenie-i-nakazanie.txt', 'r', encoding='utf8') as book:
result = [line for line in book if re.findall(r'\bРодио\w{0,3}(?:\s+\S+){0,5}\s+Раскольнико\w{0,3}\b', line)]
print(f'Найдено {len(result)} совпадений. Поиск без компиляции занял {time.time() - start:.2f} секунд')
start = time.time()
with open('prestuplenie-i-nakazanie.txt', 'r', encoding='utf8') as book:
find_name = re.compile(r'\bРодио\w{0,3}(?:\s+\S+){0,5}\s+Раскольнико\w{0,3}\b')
result2 = [line for line in book if find_name.findall(line)]
print(f'Найдено {len(result2)} совпадений. Поиск с компиляцией занял {time.time() - start:.2f} секунд')
Результат:
Найдено 5 совпадений. Поиск без компиляции занял 0.11 секунд
Найдено 5 совпадений. Поиск с компиляцией занял 0.07 секунд
Отлично! Вы освоили все основные функции для работы с регулярными выражениями.
Вы умеете применять готовые шаблоны с помощью findall, sub и search, и даже знаете, как ускорить их работу с помощью re.compile.
Но настоящая сила Regex — в умении писать собственные, даже самые сложные шаблоны. Готовы стать тем, кто не ищет их в интернете, а создает сам? В полной версии урока вас ждёт:
- Полный справочник по всем метасимволам, последовательностям и диапазонам для создания Regex-шаблонов любой сложности.
- Продвинутые техники, включая именованные группы, флаги и мощные опережающие проверки (lookarounds).
- 10 практических задач, где вы с нуля напишете регулярные выражения для парсинга, валидации и сложной замены текста.
Комментарии