
В статье рассмотрено, как машинное обучение с подкреплением может применяться для трейдинга финансовых рынков и криптовалютных бирж.
Академическое сообщество Deep Learning в основном находится в стороне от финансовых рынков. В силу ли того, что у финансовой индустрии не лучшая репутация, что решаемые проблемы не кажутся слишком интересными для исследований, или же просто из-за того, что биржевые данные трудно и дорого получать.
В этой статье показывается, что обучение с подкреплением для трейдинга финансовых рынков и криптовалют может быть чрезвычайно интересной исследовательской проблемой. Хотя эта область не получила достаточного внимания со стороны научного сообщества, обучение с подкреплением на примере трейдинга также представляет существенный интерес для развития многих смежных областей, например, обучения алгоритмических агентов для многопользовательских игр.
Эта статья не посвящена предсказанию стоимости котировок с использованием Deep Learning. В ней «с высоты птичьего полета» обсуждаются трудности машинного обучения в области трейдинга, и как оно все-таки может в нем использоваться при переходе от обучения с учителем на обучение с подкреплением. Статья не подразумевает никакого опыта в трейдинге, поэтому обсуждение начнется с самых основ. Повествование будет излагаться в терминах криптовалютных бирж, идентичных большинству финансовых рынков. Причиной является то, что эти данные легкодоступны и бесплатны, в отличие от данных финансовых рынков.
Основы микроструктуры рынка
Торговля на криптовалютных и большинстве финансовых рынков происходит посредством непрерывного двойного аукциона (double auction) с так называемым открытым биржевым стаканом котировок (order book). Простыми словами, есть покупатели и продавцы, соответствующие другу другу так, что они могут торговаться. Организатор торгов (exchange) отвечает за это соответствие. Существуют десятки бирж, на которых каждый может иметь несколько разных активов (например, Bitcoin или Ethereum против доллара США). Относительно интерфейса и представляемых данных все они выглядят практически одинаково.
Рассмотрим биржу GDAX – одного из наиболее популярных организаторов торгов. Предположим, вы хотите торговать пару BTC-USD (Bitcoin за доллары США). Перейдя на соответствующую страницу, вы увидите что-то похожее на следующее изображение.
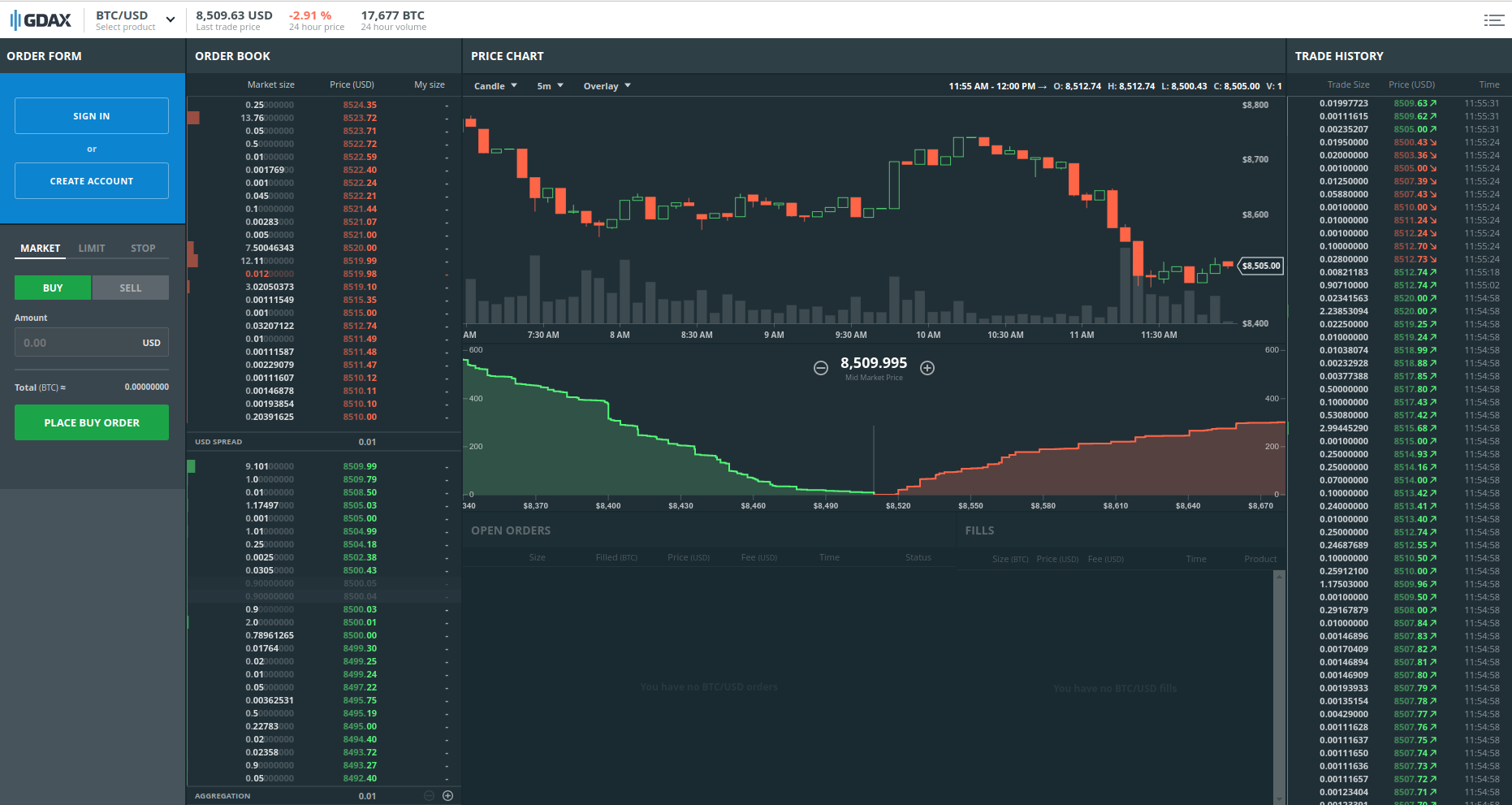
На странице довольно много информации. Рассмотрим основные элементы интерфейса.
График движения цен (Price chart)
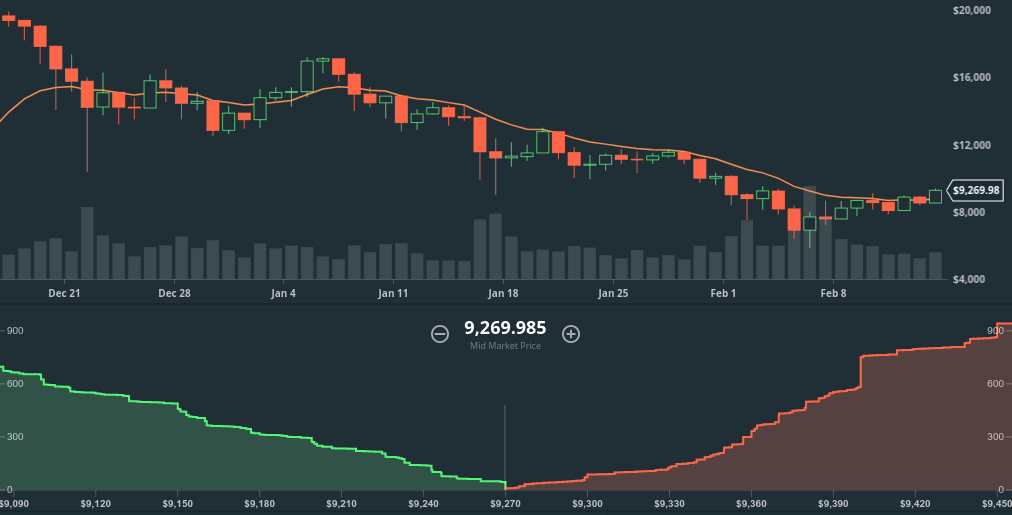
В средней части окна расположен график движения цен. В качестве текущей цены устанавливается цена последней сделки. Движение отображается в виде графика японских свечей, показывающего для отображаемого временного интервала цены начала (O) и конца (С) периода, наиболее высокое (H) и низкое (L) значение цены. На приведенной ниже картинке интервал времени составляет 5 минут, но вы можете изменить его, используя выпадающий список. Бары под графиком движения цен показывают общий объем (V) всех сделок, произошедших за этот период.
Объем важен, потому что он дает вам ощущение ликвидности рынка. Если вы хотите купить при помощи BTC 100 000 долларов, но никто не покупает Bitcoin, рынок не ликвиден. Высокий объем торговли указывает на то, что многие люди готовы совершать сделки, то есть и вы сможете продавать или покупать активы. Чем большую сумму вы готовы потратить на сделку, тем больший объем торговли вам необходим. Кроме того, ликвидность рынка означает то, что вы можете больше полагаться на движение цен, чем при низком объеме, так как большой объем сделок (в отсутствие манипулирования рынком) является консенсусом большого числа участников рынка.
Архив торговых операций (Trade History)
В правой части окна показывается история недавних торгов. Для каждой сделки указывается размер, цена и отметка времени.
Биржевой стакан (Order book)
В левой части интерфейса находится биржевой стакан, в котором содержится информация о предлагаемых сделках, по какой цене предлагается купить или продать активы. Биржевой стакан состоит из двух частей: заявок на продажу (asks) и заявок на покупку (bids). То есть asks – это предложения людей, желающих продать, а bids – заявки людей, желающих купить. Часто по-русски эти величины называют так же: аск и бид.
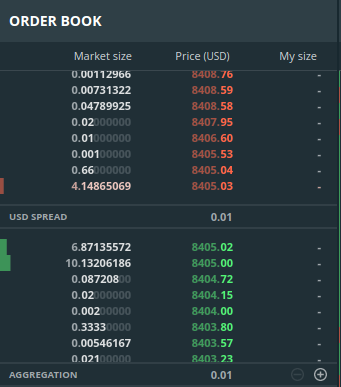
Лучшие аски и биды
По определению лучшая цена заявки на продажу (best ask) имеет наименьшую величину. Однако эта величина выше, чем best bid – лучшая цена заявки на покупку с наибольшей суммой оплаты. Иначе торговля между двумя этими сторонами уже бы произошла.
Разница между лучшим предложением и лучшим спросом называется спредом. На изображении выше best ask это 8405.03, best bid это 8405.02. То есть спред составляет всего 1 цент, что и отображается в области, разделяющей аски и биды.
Каждый уровень биржевого стакана содержит цену и объем сделки. При покупке, если вы превышаете объем сделки, доступной по best ask, оставшийся объем будет осуществлен по менее выгодным сделкам, следующим за best ask. Рассмотрим на примере изображенного выше биржевого стакана покупку 4.5 BTC. Первые 4.15 BTC (округленно) вы купите по цене 8405.03, оставшиеся 0.35 BTC уже по цене 8405.04. Кроме того, на GDAX вы также будете платить 0,3% от суммы сделки. Этот сбор существенно выше биржевых сборов как на финансовых рынках, так и на многих биржах криптовалют.
Обратите внимание, что ваша сделка при превышении объема best ask сдвигает этот уровень выше, устанавливая новую, более высокую стоимость следующих сделок. Продажа работает аналогично, но осуществляя сделку, вы уменьшаете величину best bid, то есть эта часть биржевого стакана двигается в обратном направлении. Таким образом, размещая заказы на покупку и продажу, вы извлекаете объемы из биржевого стакана. Если ваши сделки достаточно велики, вы можете существенно сдвинуть уровни биржевого стакана.
Рыночный и лимитный ордера
Каким образом соответствующие записи попадают в биржевой стакан? Различают рыночный ордер (market order) и отложенный ордер (pending order). В примере выше описывался рыночный ордер, означающий «Купить/Продать определенное количество BTC по лучшей возможной цене, прямо сейчас». Однако из рассмотренного примера следует, что если вы не следите за состоянием биржевого стакана, вы рискуете заплатить существенные больше, чем планировали. Особенно если большинство нижних уровней имеет малый объем (например, 0.001 BTC).
Одним из типов отложенных ордеров является лимитный ордер (limit order). В этом случае вы указываете цену и количество, которое хотите купить или продать по этой цене, однако для вас не является критичным вопрос времени. Например, цена BTC составляет $8 000, но вы хотите продать Bitcoin по цене $8 010. Вы устанавливаете лимитный ордер. Если цена будет двигаться вниз, с вашим ордером ничего не будет происходить, и вы можете в любое время его отменить. Однако, если цена начнет двигаться вверх, ваш ордер в какой-то момент станет лучшей ценой в биржевом стакане, и сделка состоится.
При совершении сделок по рыночным ордерам сразу уменьшается объем рынка, его ликвидность. Поэтому люди, совершающие сделки по выставленным ордерам (market takers) и уменьшающие ликвидность рынка, обычно платят больший биржевой сбор, чем те, кто создает новые записи – маркетмейкеры (market makers) и увеличивает ликвидность рынка.
Лимитные ордера обеспечивают ликвидность, так как они дают другим возможность торговать. В то же время, лимитные ордера гарантируют, что вы не заплатите выше (или не продадите ниже) установленной цены. Кроме того, при помощи лимитного ордера вы информируете других участников рынка о том, какую цену активов вы считаете приемлемой.
Это очень беглое введение в основы того, как работает биржевой стакан. Существуют и более сложные виды ордеров и определенные тонкости, связанные с ними, однако приведенной информации будет достаточно для дальнейших рассуждений.
Данные
Как упоминалось выше, одна из основных причин, почему эту статью мы иллюстрируем именно при помощи криптовалют, это публичность данных и легкий доступ к инструментам криптовалютных бирж. Так, большинство сайтов-организаторов торгов имеют соответствующий потоковый API, позволяющий получать информацию об обновлении данных рынка в режиме реального времени. В качестве примера воспользуемся документацией API биржи GDAX. Приведем несколько примеров основных типов событий, которые можно использовать для создания модели, реализующей машинное обучение с подкреплением.
Trade
Событие Trade соответствует осуществлению новой сделки. Каждая сделка имеет временную отметку, уникальный идентификатор, присвоенный организатором торгов, цену, размер, и вид сделки (side: buy или sell). Этих данных достаточно для построения графика движения цен.
{
"time": "2014-11-07T22:19:28.578544Z",
"trade_id": 74,
"price": "10.00000000",
"size": "0.01000000",
"side": "buy"
}BookUpdate
Событие BookUpdate соответствует тому, что в биржевом стакане изменились один или несколько уровней. Каждый уровень описывается типом предлагаемой сделки (buy или sell), ценой и расположением уровня.
{
"type": "l2update",
"product_id": "BTC-USD",
"changes": [
["buy", "10000.00", "3"],
["sell", "10000.03", "1"],
["sell", "10000.04", "2"],
["sell", "10000.07", "0"]
]
}BookSnapshot
Событие BookSnapshot похоже на событие BookUpdate, но делает полный снимок всего биржевого стакана. Последний может быть очень большим, поэтому обычно существенно более эффективным является использование события BookSnapshot, но иногда бывает полезна полная фиксация текущего состояния.
{
"type": "snapshot",
"product_id": "BTC-EUR",
"bids": [["10000.00", "2"]],
"asks": [["10000.02", "3"]]
}Поток вышеуказанных событий содержит всю информацию, которую вы видите в графическом интерфейсе. Попытаемся представить, как можно сделать прогноз на основе потока событий.
Несколько метрик торговой стратегии
При разработке торговых алгоритмов в первую очередь нужно задаться вопросом, какой параметр должен оптимизироваться. Один из очевидных ответов – прибыль. Но еще необходимо сравнивать рассматриваемую стратегию торгов по основным показателям с другими возможными стратегиями, а также риск стратегии и волатильность по отношению к другим видам инвестиций.
1. Чистая прибыль (чистая прибыль и убыток)
Самая простая метрика – определение прибыли и убытка на конец временного интервала с учетом соответствующих биржевых сборов.
2. Альфа- и бета-коэффициенты
Альфа-коэффициент – показатель, определяющий насколько лучше с точки зрения прибыли ваша стратегия по сравнению с альтернативными, относительно безрисковыми инвестициями, такими как государственные облигации. Даже если ваша стратегия будет прибыльной, может оказаться, что лучше инвестировать в менее рискованную альтернативу. Бета-коэффициент отражает изменчивость доходности вашей стратегии по сравнению с остальным рынком.
3. Коэффициент Шарпа
Коэффициент Шарпа – показатель эффективности стратегии, определяемый как избыток дохода на единицу принимаемого риска. Фактически это ваша отдача от капитала, скорректированная на риск. Чем выше этот коэффициент, тем лучше. То есть коэффициент учитывает как волатильность вашей стратегии, так и альтернативные безрисковые инвестиции.
4. Коэффициент максимального падения стоимости (максимальная просадка)
Максимальная просадка – мера риска, соответствующая максимальной разнице между локальным максимумом и последующим локальным минимумом. Например, максимальная просадка 50% означает, что вы в какой-то момент теряете 50% своего капитала. Чтобы вернуться к первоначальному капиталу, вам нужно вернуть 100% конечного состояния. Очевидно, что обычно стремятся к минимизации просадки.
5. Value at Risk (VaR)
Параметр Value at Risk служит стоимостной мерой риска, показывая какую часть капитала вы можете потерять в течение определенного периода времени с некоторой наперед заданной вероятностью, исходя из нормальных рыночных условий. Например, однодневный 5% VaR величиной 10% означает: есть вероятность 5%, что в течение дня вы можете потерять более 10% инвестиций.
Обучение с учителем
Прежде чем взглянуть на то, как в трейдинге может использоваться обучение с подкреплением, проанализируем, как создаются торговые стратегии при помощи обучения с учителем. Такой порядок позволит рассмотреть основные трудности построения модели и пути к разрешению имеющихся проблем обучения с учителем.
Наиболее очевидный подход, от которого мы можем отталкиваться это предсказание цены. Если мы предсказываем, что рынок будет двигаться вверх, мы можем купить актив сейчас и продать, как только рынок поднимается. Однако сразу же появляется несколько проблем.
Цена
Прежде всего, какую цену мы действительно прогнозируем? Как мы видели выше, нет одной единственной цены, по которой осуществляется сделка. Конечная цена, которую мы платим, зависит от объема, доступного на разных уровнях биржевого стакана, и комиссии биржи. Мы бы могли ответить, что мы можем предсказать среднюю цену, являющуюся промежуточной точкой между лучшей заявкой на продажу и лучшей заявкой на покупку. Это то, что делают большинство исследователей. Однако очевидно, что это лишь некоторая теоретическая цена, которая значительно отличается от цены, по которой мы платим в реальности.
Время
Следующий вопрос – какую временную шкалу мы выбираем? Предсказываем ли мы цену следующей сделки? Цену в следующую секунду, минуту, час или день? Интуитивно понятно, что чем более дальний прогноз мы хотим сделать, тем больше неопределенность и сложнее проблема прогнозирования.
Поясняющий пример
Предположим, что цена BTC составляет $10 000, и мы можем точно предсказать что «цена» изменится с $10 000 до $10 050 в следующую минуту. Означает ли это, что вы можете заработать $50 прибыли от покупки сейчас и продажи через минуту? Нет, не означает, и вот почему.
- Мы покупаем, когда лучшее предложение это $10 000. Скорее всего, мы не сможем получить весь 1.0 BTC за эту цену, так как биржевой стакан вряд ли имеет требуемый объем. Мы оказываемся вынуждены купить, например, 0.5 BTC по лучшему предложению $10 000 и оставшиеся 0.5 BTC по следующей за ним цене, например, $10 010. Тогда средняя цена составит $10 005. Также мы платим организатору торгов сбор. Для GDAX он составляет 0,3%, то есть примерно $30. Таким есть в реальности мы заплатим $10 035.
- Через минуту, как прогнозировалось, цена составила $10 050. Мы размещаем ордер на продажу. Однако рынок движется очень быстро, и к тому времени, когда заказ будет передан организатору торгов, цена уже снизилась до $10 045. Как и раньше, скорее всего мы не сможем продать по лучшей цене полностью 1.0 BTC, а также продадим, например, 0.5 BTC по текущей лучше цене $10 045, а остальные 0.5 BTC по следующему уровню биржевого стакана, например, $10 040. То есть мы продали 1.0 BTC за $10 042,5. Пусть сбор составит те же 0,3 %, то есть так же около $30. Тогда в реальности мы получим прибыль от сделки $10 012,5.
Как видите, в результате сделки мы не просто не заработали $50, а оказались в минусе: - $22,5, хотя и точно предсказали большое движение цены в течение следующей минуты. В приведенном примере этому послужило три причины:
- Отсутствие ликвидности в лучших заявках на продажу и покупку.
- Сетевые задержки.
- Сборы организатора торгов.
Политика трейдинга
Какой урок можно извлечь из приведенного примера? Чтобы заработать деньги при простой стратегии предсказания цен, мы должны прогнозировать относительно большие движения цен в течение более длительных периодов времени, а также учитывать биржевые сборы и задержку в подаче ордера. Мы могли бы сэкономить на сборах, используя лимитные ордера вместо рыночных, но тогда у нас не было бы никаких гарантий относительно соответствия наших ордеров, и нужно было бы строить сложную систему управления ордерами с возможностью их отмены.
Еще одна проблема обучения с учителем состоит в том, что оно не подразумевает какую-то линию поведения, которую далее мы будем называть политикой. В приведенном примере мы осуществили сделку, так как было предсказано повышение цены сделки, и цена действительно поднялась. Но что должен делать алгоритм, если бы цена снизилась? Продавать? Удерживать позицию? Что, если бы цена немного поднялась, а затем снова опустилась? Как должно измениться наше поведение на бирже, если мы уверены в прогнозе лишь на 65%? Все еще покупаем? Как выбрать порог для сделки или порог для размещения ордера?
Таким образом, нужна не только модель прогнозирования цен, но и некоторая политика трейдинга, основанная на правилах, учитывающих ваши прогнозы цен, и принимающих различные решения: размещение ордера, отмена ордера, ожидание изменений и т. д. Как выработать такую политику? Как оптимизировать параметры, которые ее задают и пороги принятия решений? Ответы на эти вопросы не очевидны, и многие алгоритмические трейдеры используют простые эвристики или человеческую интуицию.
Разработка торговой стратегии
К счастью, для многих из вышеперечисленных проблем есть решения. Но плохая новость заключается в том, что эти решения не очень эффективны. Рассмотрим поэтапно типичный процесс разработки торговой стратегии.
Типичный процесс разработки

- Анализ данных. Выполняется анализ данных для поиска возможности трейдинга. Результатом этого этапа является требующая проверки «идея» торговой стратегии.
- Обучение модели. При необходимости вы можете обучить одну или несколько моделей для прогнозирования доходности, необходимой, чтобы стратегия работала.
- Разработка политики. Далее вы разрабатываете политику и соответствующие правила, определяющие порядок действий на основе текущего состояния рынка и результатов обучения моделей. Эта политика может содержать параметры, требующие оптимизация, которая будет выполняться далее.
- Анализ стратегии. На этапе анализа стратегии вы проверяете разработанное решение на наборе исторических данных. Если стратегия достаточно хорошо работает при таком тестировании, можно приступать к оптимизации параметров.
- Оптимизация параметров. Теперь вы можете выполнить поиск, например, поиск по сетке, по возможным значениям параметров стратегии, таких как пороговые вероятности и коэффициенты, повторяя этап анализа стратегии и оптимизируя параметры стратегии и политики. На этом этапе является критичным возможность переобучения модели на наборе исторических данных, поэтому к задаче оптимизации нужно подходить с осторожностью и использовать несколько различных наборов данных, разбивая исходные наборы исторических данных на данные для обучения и тестирования.
- Моделирование и бумажный трейдинг. Прежде чем стратегия начинает работать «вживую», проводится моделирование разработанной стратегии трейдинга на рыночных данных, получаемых в режиме реального времени, но без реальной торговли. Такая имитация называется бумажным трейдингом, так как запись всех принятых торговых решений и отслеживание результатов осуществляется без реального открытия позиций. Этот этап помогает выявить и предотвратить переобучение, а также учесть в работе модели реальный временной отклик биржи. Если модель успешна в бумажном трейдинге, она переносится в реальное окружение.
- Живой трейдинг. На заключительном этапе стратегия развертывается на реальной бирже.
Недостатки показанного процесса
Этот сложный процесс может незначительно варьироваться в зависимости от компании или исследователя, но обычно именно в таком направлении происходит разработка новых торговых стратегий. В чем неэффективность такого процесса?
- Медленные циклы итерации процесса. Шаги 1-3 в основном базируются на интуиции, и вы не знаете, работает ли ваша стратегия, до тех пор, пока не будет выполнена оптимизация на шагах 4-5, в результате которой вы можете начать с нуля. При этом ничто не гарантирует, что следующий шаг не закончится тем же.
- До шага 4 вы не учитываете такие вещи, связанные с окружением модели, как задержки, биржевые сборы и ликвидность.
- Политика разрабатывается независимо от модели, хотя на практике они тесно связаны. Ведь прогнозы являются частью политики. Было бы более целесообразно оптимизировать их совместно.
- Политика обычно очень проста и ограничивается тем, что могут придумать люди.
- Оптимизация параметров обычно проводится неэффективно. Например, вы оптимизируете комбинацию прибыли и риска, и хотите найти параметры, дающие высокие значения коэффициента Шарпа. Вместо использования эффективного градиентного подхода обычно используется неэффективный поиск по сетке параметров.
Глубокое обучение с подкреплением для трейдинга
Обучение с подкреплением может быть описано как Марковский процесс принятия решений. Пусть есть агент (Agent) действующий в некоторой среде (Environment). Каждый раз t, когда агент принимает в качестве входного сигнала текущее состояние среды st, он принимает действие at и получает вознаграждение rt+1 и следующее состояние среды st+1. Пусть агент выбирает совершаемое им действие на основе некоторой политики π: at = π(st). Наша цель – найти политику, которая максимизирует совокупную награду Σrt за некоторый конечный или бесконечный временной интервал.
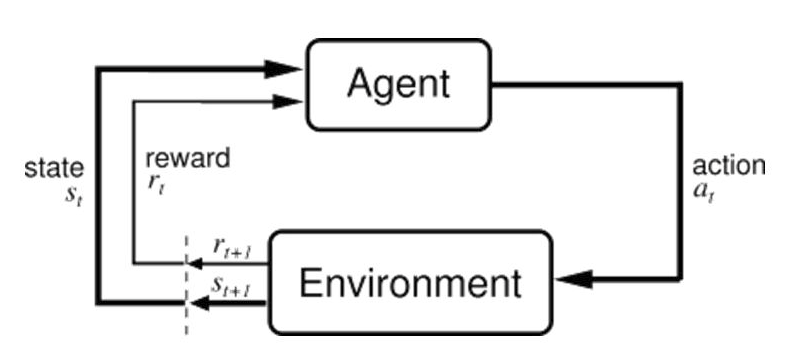
Разберемся, как термины, которые использует обучение с подкреплением, соответствуют терминологии трейдинга.
Агент
Начнем с простого. Агент – это наш торговый агент. Вы можете представлять агента как трейдера, открывающего графический интерфейс организатора торгов и принимающего решения о сделках на основе текущих состояний рынка и его счета.
Среда
Можно предположить, что средой в этом процессе является биржа. Важно отметить, что существует множество других агентов, как трейдеров-людей, так и алгоритмических игроков рынка, торгующих на одной и той же бирже. С точки зрения нашего агента эти агенты являются частью среды. Однако, объединяя сторонних агентов в одну среду, мы теряем возможность моделировать их явным образом. Например, можно вообразить, что мы могли бы научиться реконструировать алгоритмы и стратегии, которыми руководствуются другие трейдеры, а затем научиться их учитывать. Это привело бы нас к задаче настройки многоуровневого обучения (MARL), являющейся активной областью исследований в машинном обучении, о чем мы поговорим немного дальше. Пока для простоты предположим, что мы рассматриваем агентов как часть среды, с которой взаимодействует наш агент.
Состояние st
В случае трейдинга на бирже мы не видим полностью состояние среды, с которой взаимодействует наш агент. В частности, мы не знаем о том, сколько в среде имеется других агентов и каков баланс счета каждого из них. Это означает, что мы имеем дело с частично наблюдаемым Марковским процессом (POMDP). То, что наблюдает агент, это не действительное состояние системы st, а некоторая его функция xt ~ O(st).
В нашем случае наблюдение на каждой временной отметке t – это просто история всех сделок до времени. История событий может использоваться для определения текущего состояния биржи.
Временная шкала
Необходимо также решить, в какой временной шкале мы собираемся действовать. Одни трейдеры, покупают актив и удерживают его в течение нескольких дней, недель или месяцев, делая долгосрочную ставку на основе анализа вопроса вида «Будет ли Bitcoin успешным?». Эти решения обусловлены внешними событиями и новостями или фундаментальным пониманием стоимости и потенциала активов. Такой подход сложно автоматизировать методами машинного обучения. На противоположном конце от такого подхода лежат методы высокочастотного трейдинга, в котором решения основаны почти исключительно на текущем поведении рынка и принимаются в масштабах наносекунд при использовании экстремально быстрых и простых алгоритмов на FPGA-платах.
Если в первом случае требуется широкий взгляд на картину и понимание устройства рынка, то во втором случае – сверхбыстрое сопоставление с простыми шаблонами. Нейросети завоевали свою широкую популярность, так как позволили учитывать множество данных, которые не способны обрабатывать стандартные алгоритмы, такие как линейная регрессия. Но глубокие нейронные сети сравнительно медленны и не могут делать прогнозы в наносекундных временных масштабах, следовательно не могут конкурировать по времени с алгоритмами высокочастотного трейдинга. Однако они могут служить удачным компромиссом между двумя представленными крайностями, обеспечивая необходимые решения в масштабе между миллисекундами и несколькими минутами. Обучение с подкреплением имеет то преимущество перед людьми, анализирующими информацию в тех же временных масштабах, что подразумевает возможность обработки существенно большего количества специфичной анализируемой информации.
При этом в отличие от алгоритмов высокочастотного трейдинга и людей, вычисляющих определенные шаблоны поведения рынка по даваемым рынком сигналам, например, индикатору MACD, обучение с подкреплением может отслеживать эти шаблоны автоматически, а также выявлять неочевидные паттерны поведения рынка.
Обратите внимание, что агент способен работать с переменной временной шкалой, основанной на некоторых сигнальных триггерах. Например, он может принимать решения о действиях, когда на рынке произошла крупная сделка. Или, в зависимости от частоты наблюдения определенного триггера, агент может менять масштаб временной шкалы.
Пространство действий
Обучение с подкреплением предполагает необходимость различать дискретные и непрерывные пространства действий. В зависимости от того, насколько сложного агента мы хотим создать, у нас есть несколько вариантов. Самый простой агент выполняет три вида действий: Ожидать, Покупать или Продавать на определенную сумму инвестиций. В более сложных моделях агент учитывает неопределенность модели при осуществлении этих операций и варьирует сумму, то есть принимает решение о дискретном действии и непрерывной величине. Сценарий усложняется, если мы хотим, чтобы агент мог размещать лимитные ордера. В этом случае он должен уметь определить две непрерывно меняющиеся величины – цену и объем ордера. Агент также должен иметь возможность отменить открытые ордера, по которым не была совершена сделка.
Функция вознаграждения
Самой простой функцией вознаграждения могла бы служить реализованная прибыль. Агент получает вознаграждение всякий раз при закрытии позиции, например, когда продает купленный ранее актив. Чистая прибыль от этой сделки может быть положительной или отрицательной и служить сигналом награды rt. Поскольку агент стремится максимизировать совокупную награду, он учится торговать с прибылью. Однако вознаграждения происходят редко, поскольку действия по покупке и продаже в сравнении со временем ожидания сравнительно редки. Это требует, чтобы агент учился, не получая частого отклика.
Альтернативой с более частой обратной связью является нереализованная прибыль, соответствующей чистой прибыли, которую бы получил агент, если бы немедленно закрыл все свои позиции. Поскольку нереализованная прибыль меняется на каждом временном шаге, она дает агенту более частый сигнал обратной связи. Но прямая обратная связь также может стимулировать слишком частые действия агента.
Кроме указанных параметров, агент может стремиться минимизировать свой риск. Стратегия с немного более низкой отдачей и низкой волатильностью обычно предпочтительнее пусть несколько более выгодной, но очень изменчивой стратегии. Учесть риск можно при помощи упомянутых выше коэффициента Шарпа и максимальной просадки. Таким образом, вознаграждение имеет обычно вид сложной функции, учитывающей факторы связанные и с прибылью, и риском.
Машинное обучение с подкреплением
Посмотрим как обучение с подкреплением может помочь разработке торговых стратегий в сравнении с классическим машинным обучением с учителем.
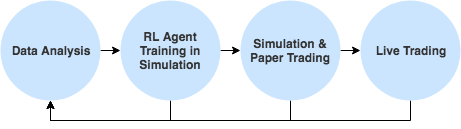
Комплексная сквозная оптимизация
В традиционном подходе к разработке стратегии мы должны были пройти конвейер из нескольких этапов прежде, чем перейти непосредственно к оптимизации метрики, о которой мы заботимся. Обучение с подкреплением позволяет осуществлять сквозную оптимизацию и максимизировать (с возможными задержками) награду. Используя функцию вознаграждения, мы можем непосредственно оптимизировать параметры, без необходимости выделения отдельных этапов. Например, мы можем ввести большую отрицательную награду, когда происходит сокращение капитала более, чем на 25%, заставляя Агента искать другую политику.
Определение политики
Вместо того, чтобы «вручную» программировать правила политики агента, наш агент может самостоятельно создавать правила своей политики. Нам не нужно указывать правила и пороговые значения в духе «покупать, когда вы на более, чем 75% уверены, что рынок будет двигаться вверх». Подобные правила политики агента в менее жесткой и более разнообразной форме будут найдены им в результате оптимизации метрики. Поскольку политика может оптимизироваться более сложной моделью глубокой нейронные сети, агент способен обнаружить более сложные и мощные политики, чем любые правила, которые могут быть предложены человеком.
Обучение с подкреплением непосредственно в моделируемой среде
В случае традиционного подхода для обучения с учителем мы нуждались в отдельных этапах проверки и оптимизации параметров, учета ликвидности заказов, структуры платежей, задержек и других. Поскольку обучение с подкреплением подразумевает, что агенты обучаются непосредственно в среде, все эти параметры учитываются на уровне отклика системы. Например, если агент не учитывает задержки, функция вознаграждения получает отрицательный результат, и агент стремится принять это в расчет, чтобы максимизировать прибыль.
Если пойти еще дальше, мы могли бы смоделировать реакцию других агентов в одной и той же среде, например, моделировать влияние, оказываемое нашими собственными ордерами. Изучая модель среды, в которой находится агент, и выполняя развертывание с использованием таких методов, как метод Монте-Карло для поиска в дереве, мы можем учитывать возможную реакцию других агентов рынка и непрерывно совершенствовать нашу модель на обновляющихся данных. Моделируя все более сложную среду, отражающую реальный мир, мы можем обучать очень сложных агентов, учащихся учитывать ограничения этой среды.
Адаптация к меняющимся условиям рынка
Известно, что стратегии определенные для одной среды, то есть соответствующие одним рыночным условиям, не будут эффективно работать в других рыночных условиях. Например, это касается стратегий «быков» и «медведей». Отчасти эта проблема связана с характером политик стратегий, не обладающих достаточной параметризацией, чтобы модель приспосабливалась к меняющимся условиям рынка.
Поскольку агенты, использующие обучение с подкреплением, изучают мощные политики, параметризованные нейронными сетями, они также могут научиться адаптироваться к различным рыночным условиям, видя их в исторических данных, учитывая, что они обучены в течение длительного времени и имеют достаточную память. Это позволяет им быть более надежными для меняющихся рынков, чем стратегии, созданные при обучении с учителем. Фактически мы можем напрямую оптимизировать их, чтобы они стали устойчивыми к изменениям рыночных условий, введя соответствующие штрафы в функцию вознаграждения.
Возможность моделирования других агентов
Уникальная способность агентов, использующих машинное обучение с подкреплением, заключается в том, что мы можем явно учитывать в моделировании других агентов. Если вместо рынка рассматривать совокупность различных агентов, мы можем научиться использовать их стратегии. Это похоже на предсказание поведения игроков в многопользовательских играх, таких как DotA.
Использование агента трейдинга для исследовательских задач
Рассмотрим, что делает криптовалютные биржи интересной исследовательской платформой для машинного обучения. В заключительной части статьи мы хотели бы раскрыть основные моменты того обучение с подкреплением на примере трейдинга может помочь развитию алгоритмов машинного обучения в смежных областях.
Тестирование в режиме реального времени и быстрые итерации циклов разработки
Обучение с подкреплением часто затруднительно или дорого развернуть их в реальном мире и получить необходимую обратную связь. Как мы упомянули выше, взаимодействие торговых агентов очень похоже на многопользовательскую игру, которую исключительно просто (в сравнении с обычными играми) протестировать вживую. Вы можете развернуть своего агента на бирже через API и сразу получать обратную связь в реальном мире. Используя концепцию бумажного трейдинга, и подсчитывая доход, вы можете сразу же видеть переобучение модели, если при оптимизации параметров вы теряете бумажные деньги. При этом время отклика минимально, так как сделки на ликвидных биржах совершаются очень часто.
Большие многопользовательские окружения
Если рассматривать рыночную среду как многопользовательскую игру с тысячами одновременного действующих агентов, это может служить хорошей моделью для самих игр вроде Poker или Dota2, в которых могут применяться разработанные здесь методы. Фактически проблема трейдинга выглядит даже более сложной, так как в этой среде происходит более быстрая смена состава участников, постоянно покидающих и присоединяющихся к торгам. С одной стороны, задача может звучать как определение моделей других агентов, с другой стороны – можно пытаться максимизировать информацию относительно политики, которой следуют другие агенты.
Исследование возможностей манипулирования рынком
В рамках моделирования есть возможность исследовать, как наше поведение может использоваться для управления поведением других агентов, действующих в той же среде. Если бы мы точно знали, какие алгоритмы выполняются на рынке, мы могли бы обмануть их действия, наперед предсказывая, когда и в каких объемах агенты будут покупать или продавать активы. То есть мы бы могли зарабатывать прибыль на чужих ошибках. Это касается и трейдеров-людей, которые обычно действуют, исходя из известных рыночных сигналов, такие как экспоненциальное скользящее среднее.
Редкие вознаграждения
Торговые агенты сравнительно редко получают вознаграждения от рынка. Большую часть времени они находятся в состоянии ожидания. Действия по покупке и продаже обычно составляют небольшую часть всех действий. Это открывает возможности для поиска новых алгоритмов и методов, основанных на редком отклике.
Аналогичный аргумент касается и относительно исследования данных. Многие из современных стандартных алгоритмов, таких как DQN или A3C, используют для исследований очень простой подход, в основном добавляя к политике случайный шум. Такой наивный случайный подход к исследованию данных почти никогда не наткнется на хорошие пары st – at. Здесь необходимы новые подходы.
Многопользовательская игра множества алгоритмических агентов
Аналогично тому, как в го и шахматах может происходить игра компьютера с самим собой, мы можем одновременно обучить большое количество конкурирующих агентов и исследовать, как динамика такого игрушечного рынка повторяет паттерны, свойственные динамике реального финансового рынка. Вы способны сталкивать агентов различного типа, с разными стратегиями и политиками, или использовать данные реального рынка в качестве контролируемого сигнала обратной связи, чтобы «заставить» агентов в симуляции коллективно вести себя, как реальный рынок.
Непрерывная временная шкала
Поскольку рынки меняются в масштабах микро- и миллисекунд, трейдинг является хорошим приближением непрерывной временной области. Мы можем не фиксировать дискретные моменты времени, а рассматривать временную шкалу, как непрерывную, и считать факт выбора времени принятия действия составляющей обучения агента. То есть агент не только решает, какие именно действия предпринять, но и когда точно их осуществить. Развитие исследований, связанных с фактором времени, полезно для многих других областей, например, робототехники.
Нестационарное непрерывное обучение с подкреплением
Рыночная среда по своей природе не стационарна. Рыночные условия постоянно меняются, агенты приходят и уходят, меняют свои стратегии. Можем ли мы обучить агентов, которые учатся адаптироваться к меняющимся рыночным условиям без того, чтобы забывать то, что они узнали раньше? Например, может ли агент успешно перейти от рынка «медведей» к рынку «быков» и обратно, не переучиваясь? Может ли агент подстроиться под другого агента, обучаясь у него взаимодействию со средой?
Перенос обучения и вспомогательные задания
Обучение с подкреплением может занять длительное время, поскольку агенту необходимо не только научиться принимать правильные решения, но и понять «правила игры». Существует несколько подходов, позволяющих обучить модель более быстро, такие как перенос обучения и использования вспомогательных заданий. Трейдинг является хорошей платформой для исследования таких новых подходов ускоренного машинного обучения.
Заключение
Целью этой статьи было дать введение в трейдинг при помощи машинного обучения с подкреплением и предложить несколько аргументов в пользу того, почему такой подход может усовершенствовать современные стратегии трейдинга и смежные области применения машинного обучения. Мы разобрали базовые термины трейдинга и метрики, которые могут применяться для машинного обучения, а также рассмотрели проблематику использования подхода машинного обучения с учителем, и как указанные трудности решаются при переходе на обучение с подкреплением.
Дополнительные материалы можно найти здесь и здесь.












Комментарии
Тема капец малоосвещенная, пишу из 2019, комиссия Gdax 0.3% да уж.... 0,075% сейчас на человеческих биржах, при чем это спот, на деривативах даже есть ребейт, вам платят за лимит.